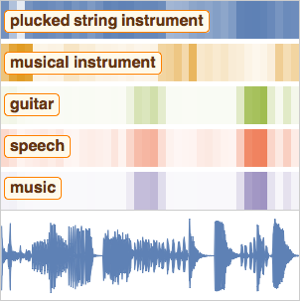
음성에 포함된 키워드 인식하기
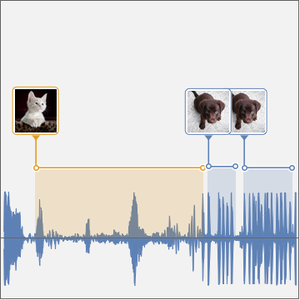
간단한 음성 전사 이외에 녹음이 특정 단어 집합 중 하나가 포함하고 있는 확률을 계산하여 네트워크에 의해 발생할 수 있는 철자 오류에 대한 어느 정도의 저항을 제공합니다. 또한 녹음의 어느 부분에 특정한 단어가 나오는지 알 수 있으면 매우 유용합니다.
Wolfram Neural Net Repository에서 훈련된 음성 인식 네트워크를 사용하여 특정 단어가 녹음에 포함되어 있는 확률을 계산합니다. 이 네트워크에 대한 자세한 내용은 이곳을 방문하기 바랍니다.
Wolfram Data Repository의 훈련 데이터 "Spoken Digit Commands"에서 샘플을 다운로드하여 시작합니다.
이 네트워크를 사용하여 항상 임의의 단일 문자의 확률을 계산합니다.
CTCLossLayer를 사용하여 네트워크의 출력에 의해 주어진 특정 문자열의 음의 로그 우도를 계산할 수 있습니다.
전사된 것이 0에서 9까지의 숫자 중 하나인 로그 우도를 계산합니다.
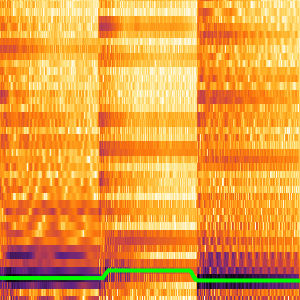
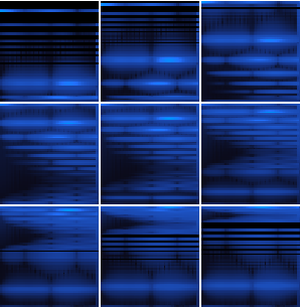
슬라이딩 윈도우를 사용하여 더 긴 음성 샘플 등의 작업을 수행할 수 있습니다.
이 네트워크를 사용하여 임의의 모든 단일 문자의 확률을 계산합니다.
전사 후보를 선택합니다.
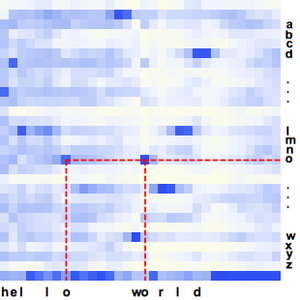
인터넷이 계산한 확률을 분할하여 신호의 부분 집합을 알아낼 수 있습니다. CTC 손실은 각 부분의 모든 선택 사항을 계산할 수 있습니다. 이것을 사용해 특정한 선택 사항이 특정 부분의 전사가 되는 로그 우도를 계산할 수 있습니다. BlockMap을 사용하여 음성 신호의 분할 부분에 함수를 적용합니다.
이제 세 단어의 확률을 시간의 함수로 플롯합니다.