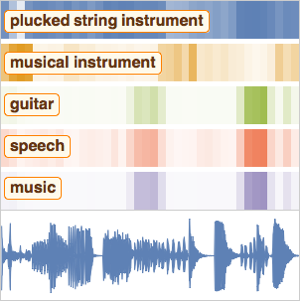
Reconheça palavras-chave em um discurso
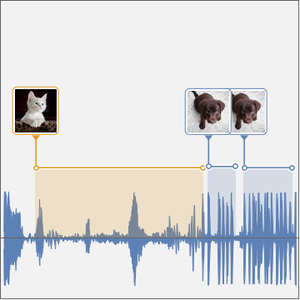
Além de uma simples transcrição de fala, calcular a probabilidade de que uma alteração de código contenha um conjunto restrito de palavras estabelece alguma resistência aos erros ortográficos que a rede pode cometer. E mais, localizar onde em uma gravação uma palavra específica é falada pode ser muito útil.
Use a rede de reconhecimento de fala pré-treinada do Wolfram Neural Net Repository para calcular a probabilidade de que uma alteração de código contenha uma palavra específica. Veja os detalhes desta rede aqui.
Comece baixando e examinando uma amostra dos dados de treinamento do "Spoken Digit Commands" do Wolfram Data Repository.
Calcule as probabilidades de uma única letra durante todo o tempo usando a rede.
Você pode usar CTCLossLayer para calcular a probabilidade negativa logarítmica de uma seqüência específica de caracteres, dado o resultado da rede.
Calcule as probabilidades logarítmicas da transcrição sendo um dos dígitos entre 0 e 9.
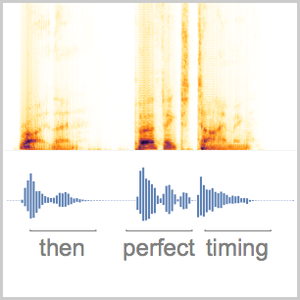
Você pode fazer a mesma operação em uma amostra de áudio mais longa usando uma janela deslizante.
Calcule as probabilidades de qualquer letra única durante todo o tempo usando a rede.
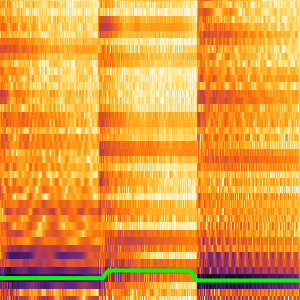
Escolha os candidatos de transcrição.
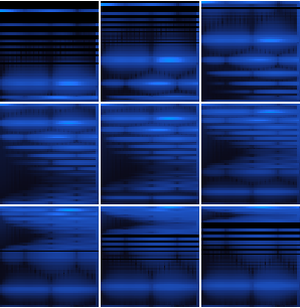
Você pode particionar as probabilidades calculadas pela rede para inspecionar subconjuntos do sinal. A perda de CTC pode ser calculada em relação a todas as escolhas para cada partição. Isso produzirá a probabilidade logarítmica de uma escolha específica, sendo a transcrição da partição específica. BlockMap é usado para aplicar a função às partições do sinal de áudio.
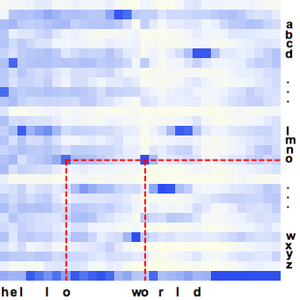
Agora você pode criar um gráfico das probabilidades das três palavras em função do tempo.