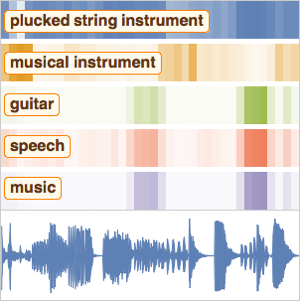
识别语音中的关键词
除了简单的语音转录之外,计算录音中包含任何禁用单词的概率还可以帮助网络避免可能产生的拼写错误。而且,定位录音中特定单词的位置也非常有用。
使用来自 Wolfram Neural Net Repository 的预先训练过的语音识别网络来计算录音包含特定单词的概率。请到此处查看有关该网络的详细信息。
从 Wolfram Data Repository 下载 "Spoken Digit Commands" 训练数据,并查看其中一个样本。
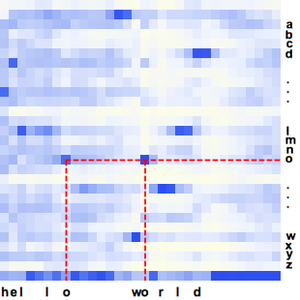
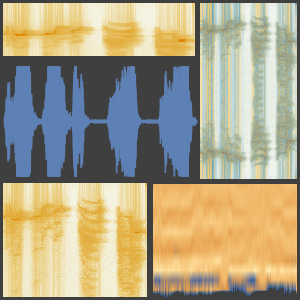
用网络计算所有时间出现任意单个字母的概率。
给定网络输出,用 CTCLossLayer 计算特定字符序列的负对数似然。
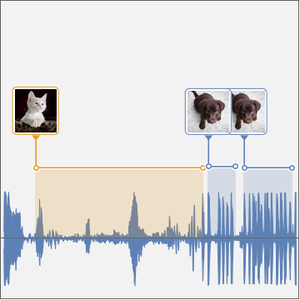
算出转录内容的对数似然值是 0 到 9 之间的一个数字。
可以使用滑动窗口对较长的音频样本执行相同的操作。
用网络计算所有时间出现任意单个字母的概率。
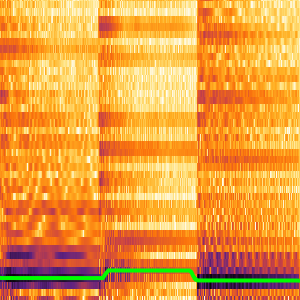
选择转录结果备选项。
可以对网络计算的概率进行划分,以检查信号的子集。可以针对每个分区的所有选择计算 CTC 损失。这将给出特定选择(特定分区的转录结果)的对数似然。用 BlockMap 将函数应用于音频信号的分区。
绘制三个单词作为时间的函数的概率。