テキスト内の実体を収集する
TextCasesとTextContentsはニューラルネットワークを使って,実体や数量的要素等のさまざまなテキストコンテンツを認識する.この例では,これらの関数がWikipediaページでどのようなことができるかを示す.
月に関するWikipediaページのテキストをロードする.
このページから注目すべきテキストの内容を抽出する.
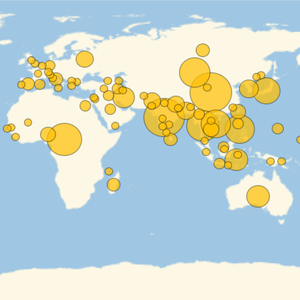
このページで見付かった内容タイプの頻度を可視化する.
ページで有名人であるかもしれないと識別された人物を見付ける.
これらの人々を実体として解釈する.
この人たちの職業を可視化する.