Entrenamiento de una red en múltiples GPU
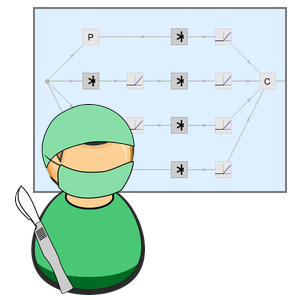
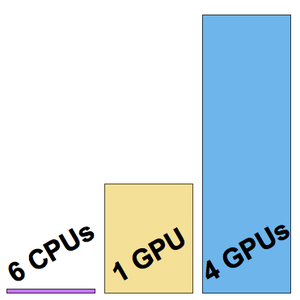
Para reducir el tiempo de entrenamiento, una red neuronal se puede entrenar en un GPU en lugar de un CPU. Wolfram Language ahora admite el entrenamiento de redes neuronales utilizando múltiples GPU (de la misma máquina), lo que permite un entrenamiento aún más rápido. El siguiente ejemplo muestra los entrenamientos en una máquina GPU de 6 CPU y 4 NVIDIA Titan X.
Cargue un subconjunto del conjunto de datos de entrenamiento CIFAR-10.
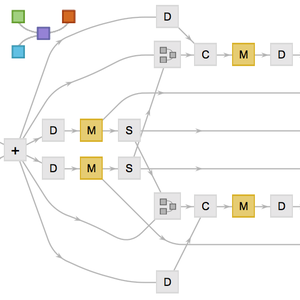
Cargue la arquitectura de "Wolfram ImageIdentify Net V1" desde Wolfram Neural Net Repository.
Preprocese los datos de entrada utilizando la red NetEncoder para evitar que el CPU preprocese cálculos de cuellos de botella de la velocidad de entrenamiento de la red.
Eliminar el ahora innecesario NetEncoder y reemplazar la cabeza de la red y la final NetDecoder para que coincidan con las clases en el conjunto de datos.
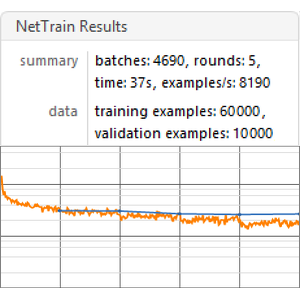
Inicie el entrenamiento en la máquina con un CPU de 6 núcleos:
Este entrenamiento se realizó a una velocidad de unos ocho ejemplos por segundo.
Inicie el entrenamiento en una sola GPU (la cuarta, ya que no se recomienda usar el GPU a cargo de la pantalla).
Esta vez, el entrenamiento se realizó a una velocidad de unos 200 ejemplos por segundo.
Ahora inicie el entrenamiento en los cuatro GPU.
La velocidad de entrenamiento es ahora de unos 500 ejemplos por segundo.
Visualice las tres velocidades de entrenamiento medidas.