训练网络模拟英语
下面的例子演示如何训练循环神经网络生成英语文本。
首先,从两部小说中创建 300,000 个训练样例,每个样例由 25 个字符组成。
对数据进行采样,以分类问题的形式给出:给定字符序列,预测下一个字符。
获取文本中所有字符的列表。
构建一个可以一次性预测整个序列的网络。请注意,在 LinearLayer 之前使用的不是 SequenceLastLayer,而是 NetMapOperator。因此,网络同时为每个字符预测下一个序列字符,而不是仅仅预测序列的最后一个字符。
现在构建一个 "teacher forcing" 网络,它取一个目标句子,并以 "staggered" 方式交给网络:对于长度为 26 的句子,将第 1 个到第 25 个字符交给网络,网络预测第 2 个到第 26 个字符,通过 CrossEntropyLossLayer 与实际出现的字符进行比较,给出损失。
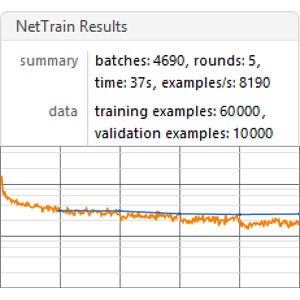
在原始数据的输入序列上训练网络。
从结果中提取预测链。
从中构建单字符预测链。
测试预测器。
创建 NetStateObject,高效生成文本。
根据网络学到的分布生成 200 个字符。生成的文本与英语有相似之处,但许多词汇甚至不是英语单词,因为它是在小型语料库(大约 200 万个字符)上训练的。
与用大约十亿字符训练过的类似网络相比。