Ein Netz zur Modellierung der englischen Sprache trainieren
Dieses Beispiel zeigt, wie man ein rekurrentes neuronales Netz trainiert, um englischen Text zu erzeugen.
Erstellen Sie zunächst 300.000 Trainingsbeispiele mit je 25 Zeichen aus zwei Romanen.
Erstellen Sie ein Sample und trainieren Sie das Modell mit einem Klassifizierungsproblem: Bei einer Folge von Zeichen prognostizieren Sie das nächste Zeichen.
Obtain the list of all characters in the text.
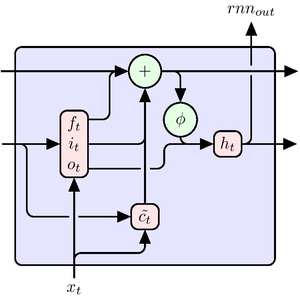
Erstellen Sie ein Netz, das eine ganze Buchstabensequenz auf einmal voraussagt. Beachten Sie, dass anstelle der Verwendung eines SequenceLastLayer vor einem LinearLayer ein NetMapOperator verwendet wird. Dadurch prognostiziert das Netz gleichzeitig das nächste Zeichen in der Sequenz für jedes Zeichen, anstatt nur das letzte Zeichen der Sequenz vorherzusagen.
Konstruieren Sie nun ein "Teacher Forcing"-Netz, das einen Zielsatz nimmt und dem Netzwerk "gestaffelt" präsentiert: Präsentieren Sie für einen Satz mit Länge 26 die Zeichen 1 bis 25 so, dass es Vorhersagen für die Zeichen 2 bis 26 erzeugt, die über den CrossEntropyLossLayer mit den realen Zeichen verglichen werden, um einen Verlust zu erzeugen.
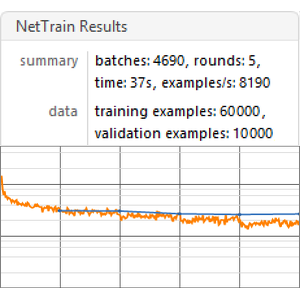
Trainieren Sie das Netz mit den Eingabesequenzen aus den Originaldaten.
Extrahieren Sie die Vorhersagekette aus den Ergebnissen.
Erstellen Sie daraus eine einstellige Vorhersagekette.
Testen Sie den Predictor.
Erzeugen Sie ein NetStateObject, um Text effizient zu erzeugen.
Erzeugen Sie 200 Zeichen entsprechend der vom Netzwerk erlernten Verteilung. Der generierte Text hat Ähnlichkeit mit dem Englischen, aber viele Wörter sind nicht einmal Englisch, weil er mit einem kleinen Korpus (etwa zwei Millionen Zeichen) trainiert wurde.
Vergleichen Sie dies mit einem ähnlichen Netz, das mit etwa einer Milliarde Zeichen trainiert wurde.