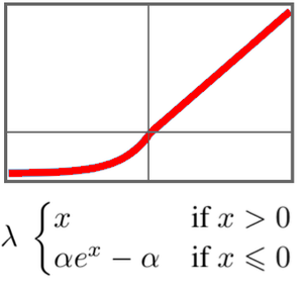
英語をモデル化するようにネットを訓練する
この例では,回帰ニューラルネットワークを訓練して英語のテキストを生成する方法を示す.
まず,2つの小説から取った,25文字の訓練例を30万例作成する.
データのサンプルを取る.このデータは,「文字列が与えられると次の文字を予測する」という分類問題の形式になっている.
テキストに含まれるすべての文字のリストを得る.
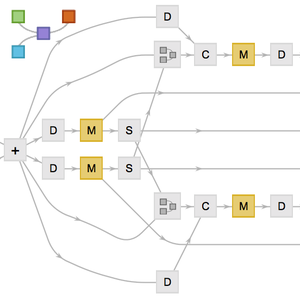
文字列全体を一度に予測するネットを構築する.LinearLayerの前にSequenceLastLayerを使うのではなく,NetMapOperatorが使われている点に注意のこと.結果として,このネットは,単に文字列の最後の文字を予測するのではなく,各文字について文字列中の次の文字を同時に予測する.
次に,対象となる文を取ってこれをネットワークに「ずらした」形式で提示する,「教師強制」ネットワークを構築する.つまり,長さ26の文について,ネットが2から26までの文字についての予測ができるように,1から25までの文字を提示する.予測は,損失を生むために,CrossEntropyLossLayerを介して実際の文字と比較される.
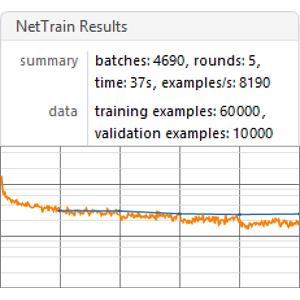
このネットをもとのデータからの入力列について訓練する.
結果から予測チェーンを抽出する.
ここから1文字の予測チェーンを構築する.
予測子を検証する.
効率的にテキストを生成するためにNetStateObjectを作成する.
ネットワークが学んだ分布に基づいて200文字を生成する.生成されたテキストは英語と類似しているが,小さいコーパス(約2百万文字)で訓練されたために,単語の多くは英語ですらない.
約10億文字で訓練された同様のネットと比較する.