強化学習環境でエージェントを訓練する
この例では,REINFORCE法(Williams, 1992)を使って「Simulated Cart Pole」環境で報酬を最大限にする簡単なニューラルネットの訓練方法を示す.カート・ポール環境は摩擦のない一次元の経路を移動するカートと,ヒンジでカートに取り付けられた重み付きの棒(倒立振り子)からなる.カートは,介入なしだと棒が倒れてしまうような初期速度を持つ.エージェントの目標は,可能な限り棒を直立の状態にしておくことである.これは2つの可能な動作(左に動くか右に動くか)のどちらをいつ行うかを学習することによって達成される.
初期状態の環境をロードし描画する.
カートを左に動かすか右に動かすかを決める方策を学習する簡単なネットを定義する.
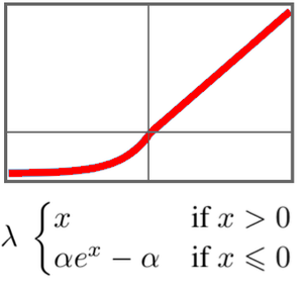
方策勾配学習の損失関数を定義する.
ネットの訓練データをサンプリングする生成器関数を定義する.
完全なWolfram言語入力を表示する
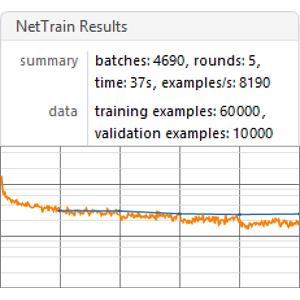
平均の割引報酬を測定して,方策ネットを訓練する.
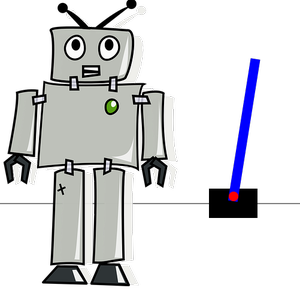
訓練された方策ネットを使って環境をアニメーション化する(以下の画像をクリックするとアニメーションが見られる).棒は直立のままであることに注目されたい.
これと,この環境でランダムな動きをするエージェントを比較する(以下の画像をクリックするとアニメーションが見られる).