Train an Audio Classifier
This example demonstrates how to train a simple neural network for audio classification and how to use it for extracting audio features.
Obtain the "Spoken Digit Commands" dataset from ResourceData, consisting of recordings of various speakers pronouncing digits from 0 to 9 along with their label and a speaker ID.
The initial encoding for audio data is more complex and more crucial than for image data. Various encoding algorithms are available for audio, including the "AudioMFCC", which produces a compact representation of the signal in terms of a sequence of vectors.
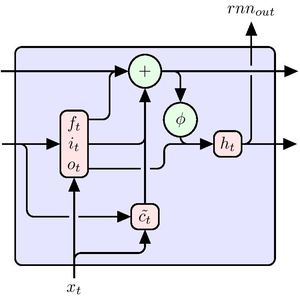
Define a classification network based on a stack of GatedRecurrentLayers. NetBidirectionalOperator can be used to make the layers bidirectional, reading the sequence in both directions and concatenating the results. The final state of the recurrence is extracted by SequenceLastLayer.
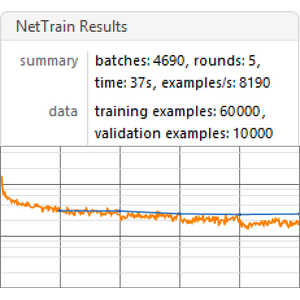
Train the net using NetTrain and keeping 5% of the data for validation.
Evaluate the final net on an example from the test set.
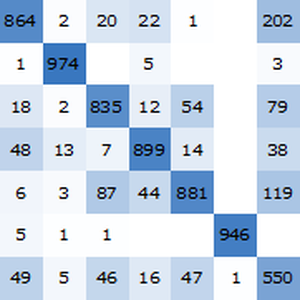
Compute the accuracy on the test set using NetMeasurements.
The net can be used as a high-level feature extractor by removing the last classification layers.
The extractor can be used to train a new model very quickly and with a small amount of data. As an example train a new classifier with Classify using only 50 training examples.
Obtain performance information about the classifier.