Visualización de los interiores de una red neuronal
Para comprender el funcionamiento interno de una red de clasificación de imágenes entrenada, puede tratar de visualizar las características de la imagen a las que responden las neuronas dentro de la red.
Cargue una red preentrenada.
Las características de la imagen de las neuronas en la primera capa de convolución están dadas simplemente por sus núcleos de convolución.
Estas neuronas codifican características de bajo nivel, como bordes y líneas en la escala de los grises y color con diferentes orientaciones.
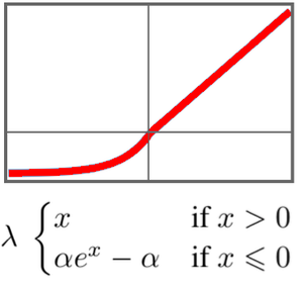
Sin embargo, este enfoque simple no funciona para las neuronas en capas que están más abajo en la cadena de procesamiento de la red. Por lo tanto, puede utilizar el algoritmo Deep Dream de Google para generar características neuronales en una imagen aleatoria de entrada.
Primero, especifique una capa y una característica que le gustaría visualizar.
Para obtener una impresión de lo que codifica una neurona, trunque la red en la capa dada y adjunte capas que extraigan la actividad cuadrada total de las neuronas especificadas.
Maximizar la salida de esta red mediante la constante actualización de una imagen aleatoria de entrada con la gradiente de propagación hacia atrás de la red resulta en una imagen que excita principalmente la neurona en cuestión. La imagen resultante muestra las características a las que responde la neurona.
Cree una imagen inicial que muestre aleatoriedad en todas las escalas.
El comando NetPortGradient["Input"] proporciona el gradiente de propagación hacia atrás en el puerto de entrada de la red. El siguiente código normaliza el coeficiente máximo del gradiente a 1/8 y lo convierte en una imagen.
Antes de actualizar iterativamente la imagen con la imagen de gradiente precedente, debe introducir una función de fluctuación que realiza un pequeño desplazamiento de la imagen.
La incorporación de una fluctuación aleatoria en el siguiente bucle ayuda a extender los artefactos locales de propagación hacia atrás, y promueve una imagen más regularizada.
La actualización 256 veces de una imagen aleatoria inicial, devuelve la siguiente imagen. Las neuronas en cuestión parecen codificar pequeños pájaros o pollos.
No dude en repetir el procedimiento anterior para otras funciones en otras capas. Notará que las neuronas en capas poco profundas codifican características simples, como las texturas, mientras que las neuronas en capas profundas codifican características más complejas, como las caras de animales.
Características de la capa de inicio 3b.
Características de la capa de inicio 4d.