Entrenamiento de un clasificador de audio
Este ejemplo muestra cómo entrenar una red neuronal simple para la clasificación de audio y cómo usarla para extraer funciones de audio.
Obtenga el conjunto de datos "Comandos de dígitos hablados" de ResourceData, que consiste en grabaciones de varios oradores que pronuncian dígitos del 0 al 9 junto con su etiqueta y una identificación del orador.
La codificación inicial para los datos de audio es más compleja y más crucial que para los datos de imagen. Varios algoritmos de codificación están disponibles para audio, incluyendo el "AudioMFCC", que produce una representación compacta de la señal en términos de una secuencia de vectores.
Definir una red de clasificación basada en una colección de GatedRecurrentLayers. NetBidirectionalOperator se puede utilizar para hacer que las capas sean bidireccionales, leer la secuencia en ambas direcciones y concatenar los resultados. El estado final de la recurrencia es extraído por SequenceLastLayer.
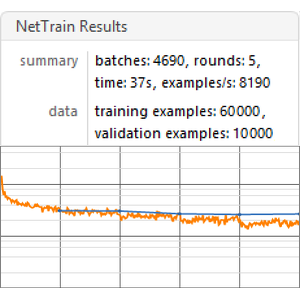
Entrene la red usando NetTrain y mantenga el 5% de los datos para su validación.
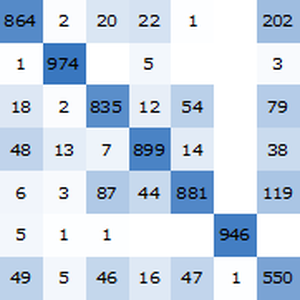
Evalúe la red final en un ejemplo del conjunto de pruebas.
Calcule la precisión en el conjunto de prueba utilizando NetMeasurements.
La red se puede utilizar como un extractor de características de alto nivel eliminando las últimas capas de clasificación.
El extractor se puede utilizar para entrenar un nuevo modelo muy rápidamente y con una pequeña cantidad de datos. Como ejemplo entrena un nuevo clasificador con Classify usando solo 50 ejemplos de entrenamiento.
Obtenga información de rendimiento acerca del clasificador.