Uso de redes neuronales tipo transformer
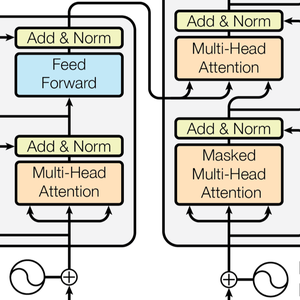
Las redes neuronales tipo transformer son una clase reciente de redes neuronales para secuencias, basadas en la autoatención, que han demostrado estar bien adaptadas al texto y actualmente están impulsando importantes avances en el procesamiento del lenguaje natural. Esta es la arquitectura como se ilustra en el trabajo seminal Attention Is All You Need.
Este ejemplo demuestra las redes neuronales tipo transformer. (GPT y BERT) y muestran cómo se pueden usar para crear un modelo personalizado para el análisis de sentimientos.
Cargue los modelos GPT y BERT desde el repositorio de la red neuronal.
Estos modelos se entrenan en grandes cuerpos de texto (generalmente miles de millones de palabras) en tareas de aprendizaje no supervisadas, como el modelado de idiomas. Como resultado, proporcionan excelentes extractores de funciones que pueden utilizarse para diversas tareas. Dada una oración, estos modelos generan una lista de vectores numéricos, uno para cada palabra o sub-palabra; estos vectores son una representación numérica del "significado" de cada palabra/sub-palabra.
Ahora explore el interior de la red BERT. Puede hacer esto haciendo clic en la parte de la red que le interese (y haciendo clic nuevamente para profundizar) o usando NetExtract.
La cadena de entrada se tokeniza primero en palabras o sub-palabras. Cada token se incrusta en vectores numéricos de un tamaño de 768.
La arquitectura del transformador luego procesa los vectores utilizando 12 bloques de auto-atención estructuralmente idénticos apilados en una cadena. La parte clave de estos bloques es el módulo de atención, constituido por 12 transformaciones paralelas de auto-atención, a.k.a. "cabezas de atención".
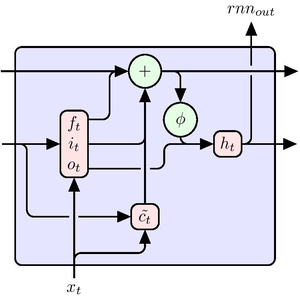
Extraiga una de estas cabezas de atención. Cada cabeza usa AttentionLayer en su centro. En pocas palabras, cada vector 768 calcula su siguiente valor (un vector 768 nuevamente) al determinar que vectores son relevantes para sí mismo. Tenga en cuenta aquí el uso de NetMapOperator.
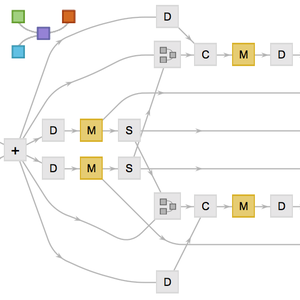
AttentionLayer puede explotar dependencias a largo plazo dentro de secuencias de una manera mucho más directa que las capas recurrentes, como LongShortTermMemoryLayer y GatedRecurrentLayer. La siguiente figura ilustra la conectividad de varias arquitecturas de secuencias.
GTP tiene una arquitectura similar a BERT. Su principal diferencia es que utiliza una autoatención causal, en lugar de una arquitectura simple de autoatención. Esto se puede ver mediante el uso de la máscara "Causal" en el AttentionLayer.
La atención causal es menos eficiente en el procesamiento de texto porque en un token dado no puede obtener información sobre tokens futuros. Por otro lado, la atención causal es necesaria para la generación de texto: GPT puede generar oraciones, mientras que BERT sólo puede procesarlas.
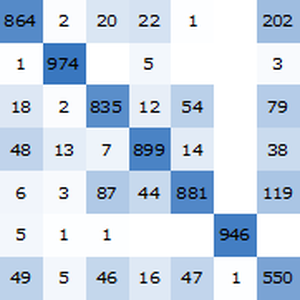
Varios artículos de investigación informan que los transformadores superan a las redes recurrentes para muchas tareas lingüísticas. Compruebe esto analizando los sentimiento de una película clásica.
Aquí GPT y BERT se comparan con las inclusiones de palabra de línea de base GloVe y ELMo, que es el estado actual de la técnica para redes recurrentes en PNL.
Algunas de las redes necesitan un poco de cirugía para poder tomar una cadena como entrada y salida de una secuencia de vectores.
Intentemos varias estrategias de agrupación para hacer un clasificador de oraciones a partir de las secuencias de inclusiones de palabras.
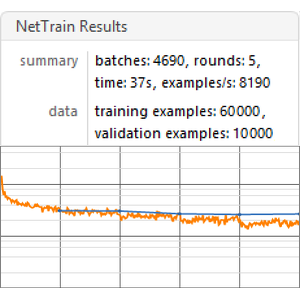
Cree una función de evaluación comparativa que entrena y mide el rendimiento de un modelo basado en una inclusión determinada.
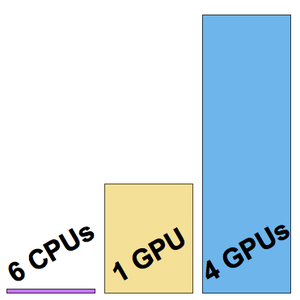
Ejecute el punto de referencia (se recomienda una GPU) en todas las inclusiones.
Visualice un informe de referencia. Como era de esperar, las inclusiones de palabras contextuales basadas en los últimos transformadores superan a las inclusiones de ELMo basadas en redes recurrentes, que superan significativamente a las inclusiones clásicas de GloVe (independientes del contexto). Tenga en cuenta que BERT es mejor que GPT (15% versus 18% de tasa de error), ya que GPT está penalizado por su restricción de causalidad.