Entrenamiento de un agente en un entorno de aprendizaje de refuerzo
Este ejemplo muestra cómo entrenar una red neuronal simple para maximizar su recompensa en el entorno simulado de "Cart Pole" utilizando el método REINFORCE (Williams, 1992). El entorno del car pole consiste en un carro que se mueve a lo largo de una pista unidimensional sin fricción y una barra que fue pesada unida al carro por una bisagra (a.k.a péndulo invertido). El carro tiene cierta velocidad inicial, de modo que la barra se caerá sin intervención. El objetivo del agente es mantener la barra en posición vertical el mayor tiempo posible. Esto se logra al aprender cuál de las dos acciones posibles (mover hacia la izquierda o hacia la derecha) se debe realizar en un momento dado.
Cargar y renderizar el entorno en su estado inicial.
Defina una red simple que aprenderá una política para elegir si mover el carro hacia la izquierda o hacia la derecha.
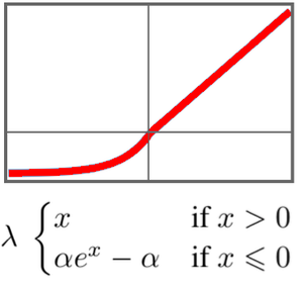
Definir una función de pérdida para el aprendizaje de gradiente de políticas.
Defina una función generadora que muestre datos de entrenamiento para la red.
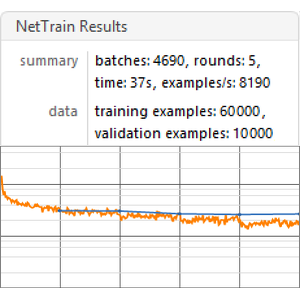
Entrene a la red de políticas, midiendo el promedio de la recompensa descontada.
Anime el entorno con la red de políticas entrenada (haga clic en la siguiente imagen para ver una animación). Observe que la barra se mantiene vertical.
Compare esto con un agente que realiza acciones aleatorias en el entorno (haga clic en la siguiente imagen para ver una animación).