Analyze Wikipedia Data
This example performs some data analysis on the complete dump of Italian Wikipedia, which, while not as large as English Wikipedia, still takes up over 13 gigabytes of uncompressed data.
The Wikimedia Foundation offers database dumps of Wikipedia that are freely downloadable following the instructions here.
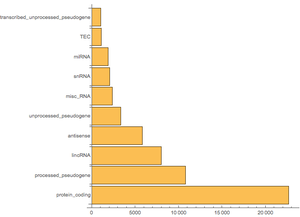
The entire Wikipedia database contains 56 tables. You are not going to need all of them, so you can selectively inspect the ones that you will need. Namely, "page", which contains information related to the page, such as the title and the length, "revision", which has an entry for each version of the page and "text", which contains the whole text of the article.
From this you can construct and register an EntityStore object.
See how many pages there are.
That is higher compared to the number quoted on the main page; as a matter of fact, Wikipedia pages are divided in namespaces: 0 are articles, 2 user pages, 4 talk pages, and so on. So if you restrict ourselves to articles you get the following.
You can compute the average length of a Wikipedia article.
Or the 10 largest articles.
Interestingly, the largest page corresponds to the history of a small region of Italy.
Another useful thing is link an article to its text. Unfortunately this is not quite easy because one of the principles of wikis is that they keep track of all revisions. Because of that, you have to go through the "revision" entity type to reach it.
Now you can use this to find the text of a particular page.
And read it as a string.
Or visualize it as a word cloud.