Wikipedia-Daten analysieren
In diesem Beispiel wird eine Datenanalyse auf der Grundlage des Dumps der italienischen Wikipedia durchgeführt. Sie ist zwar nicht so umfangreich wie die englischsprachige Wikipedia, besteht aber immerhin noch aus über 13 Gigabyte unkomprimierten Daten.
Die Wikimedia-Foundation bietet Datenbank-Dumps von Wikipedia an, die nach den Anweisungen hier kostenlos heruntergeladen werden können.
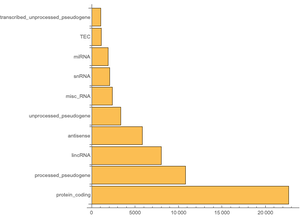
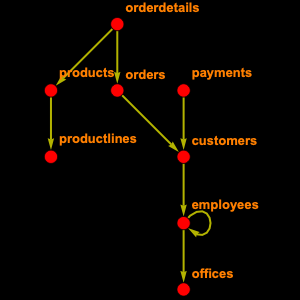
Die gesamte Wikipedia-Datenbank enthält 56 Tabellen. Da Sie nicht alle davon benötigen, können Sie nur jene, die sie brauchen, selektiv untersuchen: Nämlich "page", die Informationen über die Seite enthält, wie Titel und Länge, "revision", die für jede Version der Seite einen Eintrag hat und "text", die den gesamten Text des Artikels enthält.
Auf dieser Grundlage können Sie ein EntityStore-Objekt erstellen und registrieren.
Ermitteln Sie, wieviele Seiten es gibt.
Diese Zahl ist höher als die auf der Hauptseite angegebene Zahl; in der Tat sind Wikipedia-Seiten in Namensräume unterteilt: 0 sind Artikel, 2 Benutzerseiten, 4 Diskussionsseiten und so weiter. Wenn Sie sich also auf Artikel beschränken, erhalten Sie folgendes Ergebnis.
Sie können die Durchschnittslänge eines Wikipedia-Artikels berechnen.
Oder die zehn längsten Artikel ermitteln.
Interessanterweise befasst sich der längste Eintrag mit der Geschichte einer kleinen Region Italiens.
Eine weitere nützliche Funktion ist es, einen Artikel mit seinem Text zu verknüpfen. Leider ist dies nicht ganz einfach, denn eines der Prinzipien von Wikis ist, dass sie alle Änderungen im Auge behalten. Aus diesem Grund müssen Sie den Entitätstyp "revision" nutzen, um ihn zu erreichen.
Sie können diese Ausgabe verwenden, um den Text einer bestimmten Seite zu ermitteln.
Lesen Sie diesen als Zeichenkette ein.
Oder visualisieren Sie ihn als Word Cloud.