分割を使ってテキスト認識を向上させる
不均等な照明の下での特徴は通常正しく認識されない.
| In[1]:= |  X |
この場合TextRecognizeは失敗し,「k」という文字だけしか返さない.
| In[2]:= | X |
| Out[2]= |
テキスト認識の前に,局所的に適応型分割を使って不均等な照明を除去する.
| In[3]:= | X |
| Out[3]= |  |
| In[4]:= | X |
| Out[4]= |  |
不均等な照明の下での特徴は通常正しく認識されない.
| In[1]:= | X |
この場合TextRecognizeは失敗し,「k」という文字だけしか返さない.
| In[2]:= | X |
| Out[2]= |
テキスト認識の前に,局所的に適応型分割を使って不均等な照明を除去する.
| In[3]:= | X |
| Out[3]= | |
| In[4]:= | X |
| Out[4]= | |
 Collage of Multiple Images »
Collage of Multiple Images »
 Collage of All Images in a Dataset »
Collage of All Images in a Dataset »
 Visualize Country Population »
Visualize Country Population »
 Weighted Word Cloud »
Weighted Word Cloud »
 Foreground Separation and Removal »
Foreground Separation and Removal »
 Separate Foreground from a Similar Background »
Separate Foreground from a Similar Background »
 Replace the Image Background »
Replace the Image Background »
 Chroma Key Composition »
Chroma Key Composition »
 Use Segmentation to Improve Text Recognition »
Use Segmentation to Improve Text Recognition »
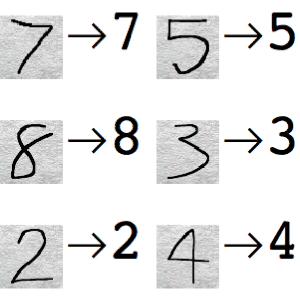 Handwritten Digits Classification »
Handwritten Digits Classification »
 Daytime/Nighttime Classification »
Daytime/Nighttime Classification »
 Gender Classification »
Gender Classification »
 Generate Barcodes of Different Formats »
Generate Barcodes of Different Formats »
 Recognize Barcodes »
Recognize Barcodes »
 Evaluate an Expression Stored in a QR Code »
Evaluate an Expression Stored in a QR Code »
 Create a Barcoded US Flag »
Create a Barcoded US Flag »
Questions? Comments? Contact a Wolfram expert »