遺伝子のDNAの共通部分配列
バージョン7の関数であるLongestCommonSequenceとLongestCommonSubsequenceに,位置を加味したLongestCommonSequencePositionsとLongestCommonSubsequencePositionsが加わった.
Y染色体のランダムな遺伝子のDNA配列を比較する.
In[1]:=
genes = RandomSample[GenomeData["ChromosomeYGenes"], 4]Out[1]=
この遺伝子をペアごとにグループ化する.
In[2]:=
With[{subsets = Subsets[genes, {2}]},
Table[pair[i] = subsets[[i]], {i, 1, Length[subsets]}]];各ペアに共通の最長DNA配列の位置を配列自体とともに求める関数を定義する.
In[3]:=

commonDNASubequence[{g1_, g2_}] :=
With[{d1 = GenomeData[g1], d2 = GenomeData[g2]}, {{g1, g2},
LongestCommonSubsequencePositions[d1, d2],
LongestCommonSubsequence[d1, d2]}]最初のペアの最長共通部分列.
In[4]:=
commonDNASubequence[pair[1]]Out[4]=
2番目のペアの最長共通部分列.
In[5]:=
commonDNASubequence[pair[2]]Out[5]=
3番目のペアの最長共通部分列.
In[6]:=
commonDNASubequence[pair[3]]Out[6]=
4番目のペアの最長共通部分列.
In[7]:=
commonDNASubequence[pair[4]]Out[7]=
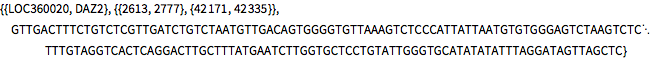
5番目のペアの最長共通部分列.
In[8]:=
commonDNASubequence[pair[5]]Out[8]=
6番目のペアの最長共通部分列.
In[9]:=
commonDNASubequence[pair[6]]Out[9]=