유전자의 일반적인 DNA 부분 배열
버전 7에 소개되었된 LongestCommonSequence와 LongestCommonSubsequence에 위치적 카운터파트를 가미하여 LongestCommonSequencePositions과 LongestCommonSubsequencePositions으로 새롭게 단장하였습니다.
Y 염색체의 랜덤 유전자의 DNA 염기 서열을 비교합니다.
In[1]:=
genes = RandomSample[GenomeData["ChromosomeYGenes"], 4]Out[1]=
유전자를 쌍으로 그룹화합니다.
In[2]:=
With[{subsets = Subsets[genes, {2}]},
Table[pair[i] = subsets[[i]], {i, 1, Length[subsets]}]];각 쌍에 공통으로 적용하는 가장 긴 연속적인 DNA 서열의 위치를 배열 자체와 함께 구하는 함수를 정의합니다
In[3]:=

commonDNASubequence[{g1_, g2_}] :=
With[{d1 = GenomeData[g1], d2 = GenomeData[g2]}, {{g1, g2},
LongestCommonSubsequencePositions[d1, d2],
LongestCommonSubsequence[d1, d2]}]첫번째 쌍의 최장 공통 부분열을 알아봅니다.
In[4]:=
commonDNASubequence[pair[1]]Out[4]=
두번째 쌍의 최장 공통 부분열을 살펴봅니다.
In[5]:=
commonDNASubequence[pair[2]]Out[5]=
세번째 쌍의 최장 공통 부분열을 살펴봅니다.
In[6]:=
commonDNASubequence[pair[3]]Out[6]=
네번째 쌍의 최장 공통 부분열을 살펴봅니다.
In[7]:=
commonDNASubequence[pair[4]]Out[7]=
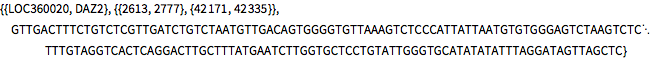
다섯번째 쌍의 최장 공통 부분열을 살펴봅니다.
In[8]:=
commonDNASubequence[pair[5]]Out[8]=
여섯번째 쌍의 최장 공통 부분열을 살펴봅니다.
In[9]:=
commonDNASubequence[pair[6]]Out[9]=