Lei de Zipf
A lei de Zipf afirma que no conjunto de dados de uma linguagem, a frequência de uma palavra é inversamente proporcional a sua posição na lista global de palavras depois de classificadas por sua frequência de forma descendente. Este exemplo demonstra a lei com um conjunto de palavras do livro de Miguel de Cervantes, Don Quixote, usando as novas funções WordCount e WordCounts.
ExampleData contém o texto em espanhol do primeiro volume de Don Quixote.
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];A amostra considerada aqui é composta por mais de 180.000 palavras.
WordCount[textSpanish]As contagens de cada palavra distinta são dadas em uma associação por WordCounts. O resultado já é classificado por contagens decrescentes.
association = WordCounts[textSpanish];Take[association, 10]Considere a contagem das primeiras 1.000 palavras mais frequentes.
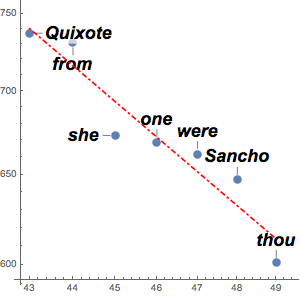
counts = Take[Values@association, 1000];Para aproximar tais contagens com uma lei poderosa, pegue algoritmos para usar um ajuste linear. A lei de Zipf afirma que o expoente deve ser aproximadamente 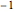 , e o resultado é um valor próximo.
, e o resultado é um valor próximo.
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Visualize o ajuste junto com os dados atuais.

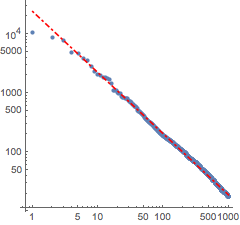
A lei de Zipf é aplicável em qualquer linguagem, assim o mesmo cálculo pode ser realizado com a versão em inglês de Don Quixote.
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];Take[associationEnglish, 10]De novo, o expoente encontrado é próximo de 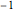 .
.
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]