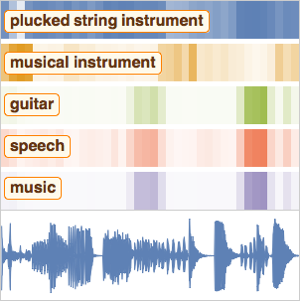
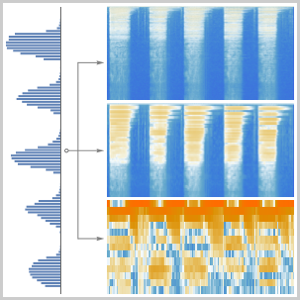
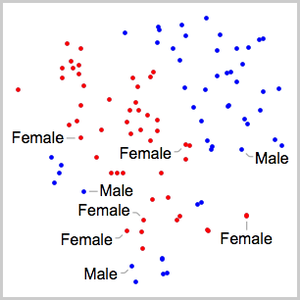
Efficient Audio Encoders
For large-scale training to be practical, an efficient way of getting data into the network is needed. The audio NetEncoder provides the efficient, low-level functionality that is required in those cases.
You can use a dataset available in the Wolfram Data Repository to measure the efficiency of the encoders. The dataset is fairly small (it is a subset of Google's Speech Commands dataset), containing 10,000 short training examples.
Select a single example.
The audio encoders support online pre-processing operations such as normalization, resampling and trimming/padding. Compare the timing of the "Audio" encoder using normalization to a simple call to AudioNormalize.
Compare the timing of the "AudioSpectrogram" encoder and the equivalent system function on the whole dataset.
Compare the timing of the "AudioSpectrogram" encoder and the equivalent system function on a collection of out-of-core Audio objects.
Compare the total time taken to encode a dataset of in-core Audio objects with top-level code and NetEncoder as a function of dataset size.
Compare the total time taken to encode a dataset of out-of-core audio files with top-level code and NetEncoder as a function of dataset size.