Train a Sound Event Detection Net
In some cases, you want to train a network to locate sound events in a recording, but you only have access to "weakly labeled" data, where the labels only state if a certain event was present in a recording, but not where. Despite the limitation of the data, it is possible to obtain good results in sound event localization through training on weakly labeled data.
Retrieve the Audio Cats and Dogs dataset from the Wolfram Data Repository.
The dataset is comprised of annotated recordings of cats and dogs.
The duration of the recordings varies between one and 18 seconds.
You can manipulate the dataset into a format that will be friendly for training a neural net and split it into a training and a testing subset.
Inspect the cumulative duration of the training data.
And the testing data.
The "AudioMelSpectrogram" encoder is used to feed the audio signal into the network. Since the amount of data is relatively small, you can perform data augmentations to make the training more effective.
The net itself is based on a stack of recurrent layers (GatedRecurrentLayer) and an AggregationLayer to pool the result in the time dimension. This allows the net to output a single classification result instead of a sequence.
Start the training.
Extract the trained net and replace the encoder with one without augmentations.
Produce a report of its performance on the test set.
By removing the AggregationLayer and reattaching the SoftmaxLayer to the chopped net, you obtain a network that returns a sequence of class probabilities instead of a single classification result.
Define a function that takes the output of the network and returns an association of TimeSeries with the probabilities for the possible labels.
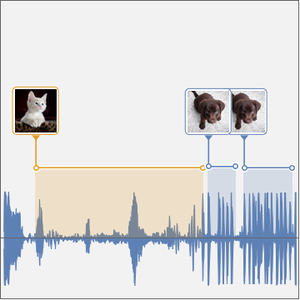
You can now test this time-resolved net. Construct a signal by joining cat and dog samples from the test dataset.
Plot the time series of the probabilities computed by the net.
Plot the net results over the test signal.
Define a function to compute the time intervals where the probability of a class is higher than a threshold and another one to compute rectangles corresponding to those intervals.
Compute the intervals.
Plot the intervals over the waveform of the recording.