Recognize Keywords in a Speech
In addition to a simple speech transcription, computing the probability that a recoding contains any of a restricted set of words provides some resistance to the spelling mistakes that the network might make. Even more, locating where in a recording a specific word is spoken can be very useful.
Use the pre-trained speech recognition network from the Wolfram Neural Net Repository to compute the probability that a recoding contains a specific word. See the details for this network here.
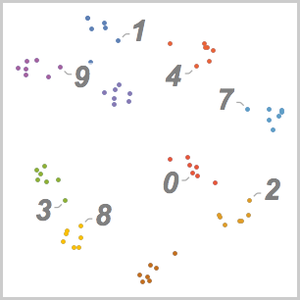
Start by downloading and looking at a sample from the "Spoken Digit Commands" training data from the Wolfram Data Repository.
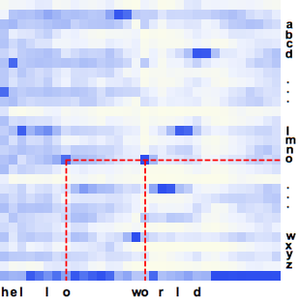
Compute the probabilities of any single letter at all times using the net.
You can use the CTCLossLayer to calculate the negative log-likelihood of a specific sequence of characters given the output of the net.
Compute the log-likelihoods of the transcription being one of the digits between 0 and 9.
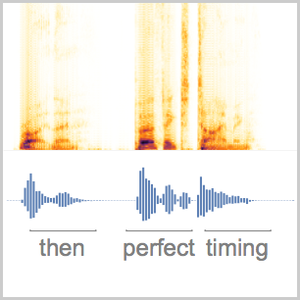
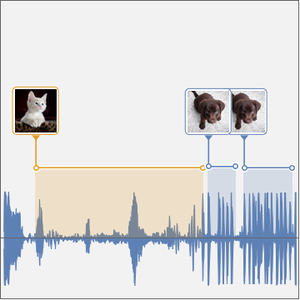
You can do the same operation on a longer audio sample using a sliding window.
Compute the probabilities of any single letter at all times using the net.
Choose the transcription candidates.
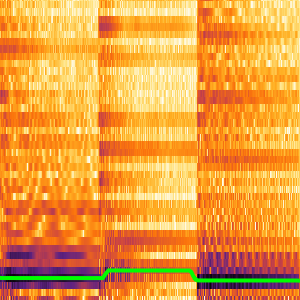
You can partition the probabilities computed by the net to inspect subsets of the signal. The CTC loss can be computed with respect to all of the choices for each partition. This will produce the log-likelihood of a specific choice being the transcription of the specific partition. BlockMap is used to apply the function to partitions of the audio signal.
You can now plot the probabilities of the three words as a function of time.