Classify Spoken Digits
The neural net framework in the Wolfram Language enables powerful and user-friendly network training tools for Audio objects. This example trains a net to classify spoken digits.
Retrieve the Spoken Digit Commands datasets from the Wolfram Data Repository.
The dataset is comprised of recordings of the digits from 0 to 9. It is essentially an audio equivalent to the MNIST digit dataset.
You can start by deciding how a recording will be transformed into something that a neural network can use. The "AudioMFCC" net encoder is used, where the signal is split into overlapping partitions and some processing is applied to each to reduce the dimension while preserving information that is important for understanding the signal.
The network will be based on a simple NetChain of GatedRecurrentLayers. Since you are interested in a single classification, the recurrent layers are followed by a SequenceLastLayer and a linear classifier.
You can train the net, letting NetTrain worry about all hyperparameters.
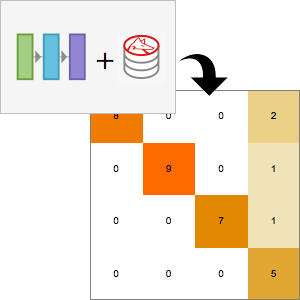
Compute the performance of the net using NetMeasurements.
By removing the last classification layers, you can obtain a feature extractor for audio signals.
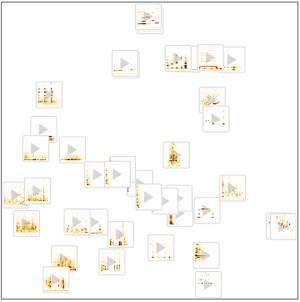
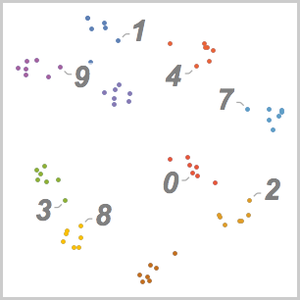
Use FeatureSpacePlot to to visualize the test dataset embedded in a feature space defined by the net you trained.