Treine uma rede em vários GPUs
Para reduzir o tempo de treinamento, uma rede neural pode ser treinada em um GPU em vez de em CPUs. A Wolfram Language agora suporta treinamento de redes neurais usando vários GPUs (da mesma máquina), permitindo um treinamento ainda mais rápido. O exemplo a seguir mostra treinamentos em uma máquina GPU 6-CPU e 4-NVIDIA Titan X.
Carregue um subconjunto do conjunto de dados de treinamento CIFAR-10.
Carregue a arquitetura do "Wolfram ImageIdentify Net V1" do Wolfram Neural Net Repository.
Pré-processe os dados de entrada usando a rede NetEncoder para evitar gargalos no pré-processamento da CPU da velocidade de treinamento da rede.
Remova o NetEncoder agora desnecessário e substitua a cabeça de rede e o NetDecoder final para que correspondam às classes no conjunto de dados.
Inicie o treinamento na máquina com uma CPU de 6 núcleos:
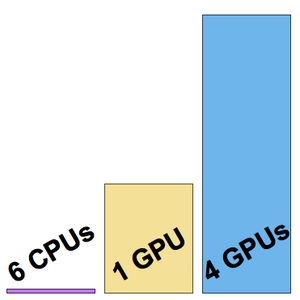
Este treinamento foi realizado a uma velocidade de cerca de oito exemplos por segundo.
Inicie o treinamento em um único GPU (o quarto, já que não é recomendado usar o GPU responsável pela exibição).
Desta vez, o treinamento foi realizado a uma velocidade de cerca de 200 exemplos por segundo.
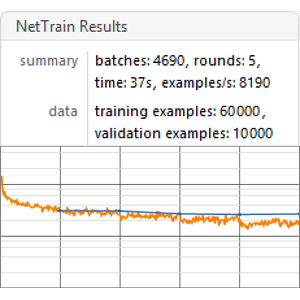
Agora, inicie o treinamento em todos os quatro GPUs.
A velocidade de treinamento é agora de cerca de 500 exemplos por segundo.
Visualize as três velocidades de treinamento medidas.