Train a Net to Model English
This example demonstrates how to train a recurrent neural network to generate English text.
First, create 300,000 training examples of 25 characters each from two novels.
Sample the data, which is in the form of a classification problem: given a sequence of characters, predict the next character.
Obtain the list of all characters in the text.
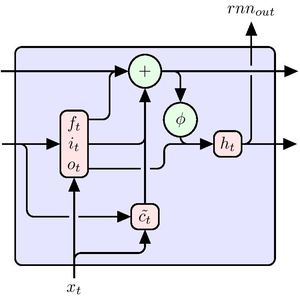
Build a net that predicts an entire sequence at once. Note that rather than using a SequenceLastLayer before a LinearLayer, a NetMapOperator is used. As a result, the net simultaneously predicts the next character in the sequence for each character, rather than just predicting the last character of the sequence.
Now build a "teacher forcing" network, which takes a target sentence and presents it to the network in a "staggered" fashion: for a length-26 sentence, present characters 1 through 25 to the net so that it produces predictions for characters 2 through 26, which are compared with the real characters via the CrossEntropyLossLayer to produce a loss.
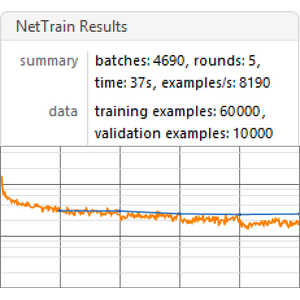
Train the net on the input sequences from the original data.
Extract the prediction chain from the results.
Build a single-character prediction chain from it.
Test the predictor.
Create a NetStateObject to generate text efficiently.
Generate 200 characters according to the distribution learned by the network. The text generated has similarity with English, but many words are not even English, because it was trained on a small corpus (about two million characters).
Compare with a similar net trained on about one billion characters.