Wikipedia 데이터 분석하기
이 예는 이탈리아어 Wikipedia의 전체 덤프에 대한 데이터 분석을 실시합니다. 이탈리아어 Wikipedia는 영어의 내용만큼 크지는 않지만, 그래도 13 기가 바이트 이상의 압축되지 않은 텍스트를 포함합니다.
Wikimedia Foundation은 Wikipedia의 데이터베이스 덤프를 제공합니다. 이것은 여기에 포함된 지침에 따라 무료로 다운로드할 수 있습니다.
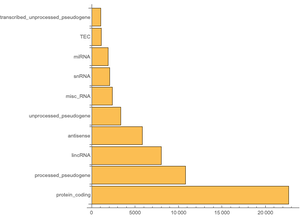
Wikipedia 전체 데이터베이스에는 56개의 테이블이 포함되어 있으며, 이 모두가 필요하지는 않으므로 필요한 것만 확인하고 선택합니다. 즉, 제목 및 길이 등의 페이지와 관련된 정보를 포함하는 "page", 페이지의 모든 버전에 대한 항목을 포함하는 "revision", 기사의 전체 텍스트를 포함하는 "text"가 필요합니다.
여기에서 EntityStore 개체를 구축하여 등록할 수 있습니다.
몇 페이지가 있는지를 조사합니다.
이 숫자는 메인 페이지에 나와있는 숫자보다 약간 많습니다. 이것은 Wikipedia 페이지가 0은 기사, 2는 사용자 페이지, 4는 토크 페이지 등 이름 공간으로 분할되어 있기 때문입니다. 따라서 기사로만 한정하면 다음과 같은 숫자를 얻을 수 있습니다.
Wikipedia 기사의 평균 길이를 계산합니다.
가장 긴 기사 열 개를 찾습니다.
흥미롭게도, 가장 큰 Wikipedia 페이지는 이탈리아의 작은 지역 역사에 대한 페이지입니다.
또 하나의 유용한 것으로 기사를 텍스트와 연관짓는 것이 있지만, 이것은 유감스럽게도 그다지 쉬운 일이 아닙니다. Wikipedia의 원칙 중 하나는 지금까지의 텍스트 "개정" 을 모두 기록해 두는 기능이 있기 때문입니다.
이제 특정 페이지의 텍스트를 찾을 수 있습니다.
이를 문자열로 읽습니다.
또는 워드 클라우드로 시각화합니다.