基因的常见 DNA 子序列
版本 7 中的函数 LongestCommonSequence 和 LongestCommonSubsequence 现在得到了其位置配对 LongestCommonSequencePositions 和 LongestCommonSubsequencePositions 的补充.
对比随机的 Y 染色体基因的 DNA 序列.
In[1]:=
genes = RandomSample[GenomeData["ChromosomeYGenes"], 4]Out[1]=
将这些基因配对分组.
In[2]:=
With[{subsets = Subsets[genes, {2}]},
Table[pair[i] = subsets[[i]], {i, 1, Length[subsets]}]];定义获取每对共有的最长连续的 DNA 序列位置以及序列本身的函数.
In[3]:=

commonDNASubequence[{g1_, g2_}] :=
With[{d1 = GenomeData[g1], d2 = GenomeData[g2]}, {{g1, g2},
LongestCommonSubsequencePositions[d1, d2],
LongestCommonSubsequence[d1, d2]}]第一对最长共有子序列.
In[4]:=
commonDNASubequence[pair[1]]Out[4]=
第二对最长共有子序列.
In[5]:=
commonDNASubequence[pair[2]]Out[5]=
第三对最长共有子序列.
In[6]:=
commonDNASubequence[pair[3]]Out[6]=
第四对最长共有子序列.
In[7]:=
commonDNASubequence[pair[4]]Out[7]=
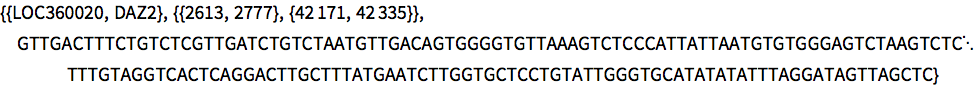
第五对最长共有子序列.
In[8]:=
commonDNASubequence[pair[5]]Out[8]=
第六对最长共有子序列.
In[9]:=
commonDNASubequence[pair[6]]Out[9]=