Анализа и сравнение продуктов питания "Superfoods"
В данном примере речь пойдет о продуктах с очень высоким содержанием одного или нескольких питательных веществ. Мы рассмотрим набор таких "супер-продуктов" и противопоставим их более "типичным" продуктам. Для этого, мы воспользуемся данными о продуктах питания из базы знаний Wolfram Knowledgebase. Мы определим отличительные характеристики, подходящие для определения пищевых продуктов, достойных эпитета "супер".
Для начала, определим список супер-продуктов с высоким содержанием питательных веществ.

superfoodsRawData = {{"greek yogurt", {"TotalProtein"}}, {"quinoa", \
{"TotalProtein"}}, {"blueberries", {"TotalFiber",
"VitaminC"}}, {"kale", {"TotalFiber", "Calcium",
"Iron"}}, {"chia", {"Magnesium", "Iron", "Calcium",
"Potassium"}}, {"oatmeal", {"TotalFiber"}}, {"broccoli", \
{"TotalFiber", "VitaminC",
"TotalFolate"}}, {"strawberries", {"VitaminC"}}, {"salmon", \
{"TotalProtein"}}, {"watermelon", {"TotalSugar", "VitaminA",
"VitaminC", "TotalCalories"}}, {"lima beans", {"TotalFiber"}},
{"edamame", {"TotalFiber"}}, {"spinach", {"Calcium",
"VitaminK"}}, {"pistachios", {"TotalProtein", "TotalFiber",
"Potassium"}}, {"eggs", {"TotalProtein"}}, {"almonds", \
{"TotalFiber", "Potassium", "Calcium", "VitaminE", "Magnesium",
"Iron"}}, {"pumpkin", {"BetaCarotene"}}, {"apples", \
{"TotalFiber", "TotalCalories"}}, {"lentils", {"TotalProtein",
"Iron"}}};Преобразуем эту информацию в набор данных, Dataset, для упрощения вычислений.
superfoodsDatset =
Dataset[<|"Food" -> #1, "Nutrients" -> #2|> & @@@ superfoodsRawData]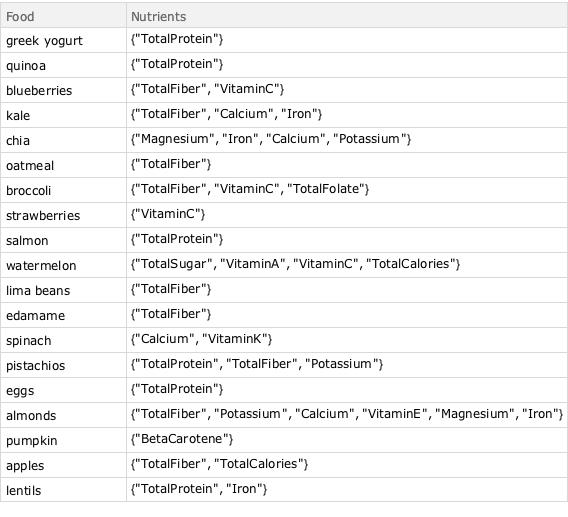
Воспользуемся функцией Interpreter языковых объектов Wolfram Language для супер-продуктов.

superfoodsDatset1 =
superfoodsDatset[All,
KeySort[Prepend[#, <|
"FoodEntity" -> Interpreter["Food"][#Food]|>]] &];Перечислим питательные вещества, содержащиеся в этих продуктах.
Union @@ Normal[superfoodsDatset1[[All, "Nutrients"]]]Генерируем правила для преобразования данных питательных веществ в их соответствующие свойства.

superfoodsDatset2 =
superfoodsDatset1 /.
AssociationMap[
EntityProperty["Food", "Relative" <> # <> "Content"] &,
Union @@ Normal[superfoodsDatset1[[All, "Nutrients"]]]]
Определим наиболее распространенные питательные вещества в нашем наборе данных, Dataset.
mostCommonProperties =
superfoodsDatset2[Counts[Flatten[#]] &, "Nutrients"][TakeLargest[5]]
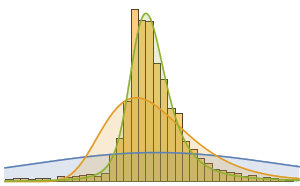
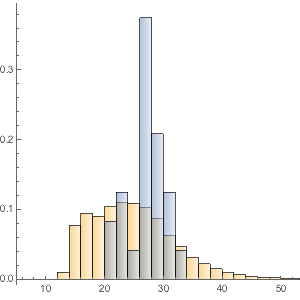
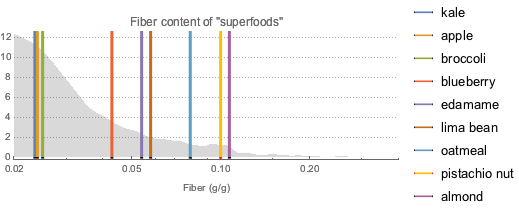
Определим суперпродукты с высоким содержанием клетчатки и сравним их с почти 9000 других пищевых продуктов. Визуализируем эти данные с помощью сглаженной гистограммы, на которой серая кривая показывает функцию плотности вероятности содержания волокон клетчатки в данных продуктах питания.

fiberDataset =
superfoodsDatset2[
Select[ContainsAny[#Nutrients, {EntityProperty["Food",
"RelativeTotalFiberContent"]}] &], KeyDrop["Nutrients"]];


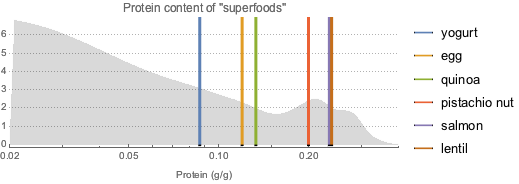
Проведем похожий анализ для супер-продуктов, богатых белком.
proteinDataset =
superfoodsDatset2[
Select[ContainsAny[#Nutrients, {EntityProperty["Food",
"RelativeTotalProteinContent"]}] &], KeyDrop["Nutrients"]];


Создадим визуальные обозначения для супер-продуктов. Для этого, подберем подходящие изображения.

GraphicsGrid[
Partition[
ims = EntityValue[
Cases[superfoodsDatset2[All, "FoodEntity"] // Normal,
Entity["FoodType", _], Infinity], "Image"], UpTo[5]]]
В качестве схемы изображения, воспользуемся эмблемой супермена.
Entity["Lamina", "SupermanInsigniaLamina"]["Image"] // ImageCrop
Воспользуемся простым способом обработки изображений для преобразования изображения эмблемы супермена в фоновое изображение.

background =
ColorNegate[
Binarize[Entity["Lamina", "SupermanInsigniaLamina"]["Image"], .99]]
Создадим облако, состоящее из изображений супер-продуктов.
wc = WordCloud[(RandomReal[{0.6, 1.2}] -> #) & /@ ims, background]
Совместим облако и подготовленных ранее фон.
ImageMultiply[{ColorReplace[background, Black -> LightGray], wc}]