시계열을 사용한 음성 생성
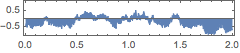
일정하게 샘플 된 TimeSeries의 사인파 주파수를 제어합니다.
In[1]:=

n = 50;
frequencies = RandomReal[{100, 300}, n];
reg = TimeSeries[frequencies, {0, Automatic, .3}];In[2]:=
AudioGenerator[{"Sin", reg}]Out[2]=
불규칙하게 샘플 된 TimeSeries의 사인파 주파수를 제어합니다.
In[3]:=
times = Accumulate[RandomReal[{0.1, .5}, n]];
irreg = TimeSeries[frequencies, {times}];In[4]:=
AudioGenerator[{"Sin", irreg}]Out[4]=
WhiteNoiseProcess를 사용하여 백색 소음을 생성합니다.
In[5]:=
sample = RandomFunction[WhiteNoiseProcess[1/3], {88200}]Out[5]=
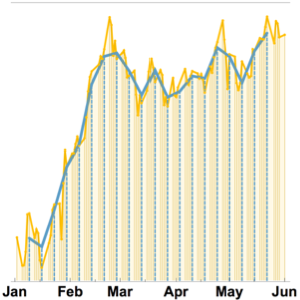
샘플을 2초 길이로 다시 스케일하여 음성을 생성합니다.
In[6]:=
AudioNormalize@
AudioGenerator[TimeSeriesRescale[sample, {0, 2, 1/44100}]]Out[6]=
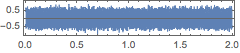
In[7]:=
AudioNormalize@
AudioGenerator[TimeSeriesRescale[sample, {0, 2, 1/44100}]];
AudioPlot[%]Out[7]=
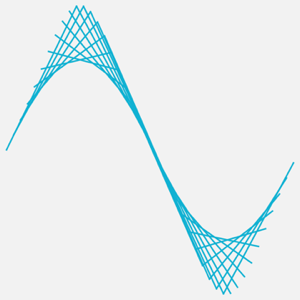
FractionalGaussianNoiseProcess를 직접 사용하여 다른 유형의 노이즈를 생성합니다.
In[8]:=
AudioNormalize@AudioGenerator[FractionalGaussianNoiseProcess[1/3], 2]Out[8]=
In[9]:=
AudioNormalize@AudioGenerator[FractionalGaussianNoiseProcess[1/3], 2];
AudioPlot[%]Out[9]=