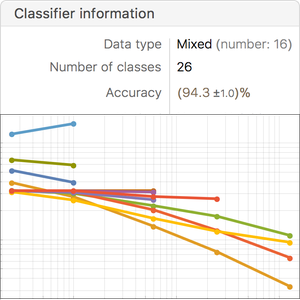
数値データの外れ値を見付ける
外れ値(異常)とは,他のほとんどのデータ点からかけ離れているデータ点として定義することができる.この例では簡単な数値データ集合を使って異常の見付け方および異常検出と「より低い確率」という概念を関連付ける方法を説明する.
FisherのIris(アヤメ)データ集合をロードし,属性"PetalLength"(花弁の長さ)と"SepalWidth"(萼片の幅)を選ぶ.
データ集合の外れ値を見付ける.
データの他の部分と比較した外れ値の位置を可視化する.
異常検出器関数はデータから得ることもできる.
検出関数を使って外れ値を見付ける.
特定の例に検出器関数を使う.
それぞれの異常検出器には異常ではないとされたデータ点で訓練されたLearnedDistributionが含まれている.この分布から新しい例のRarerProbabilityが計算できる.
より低い確率は,どの例が外れ値であるかを定義するために使われる.デフォルトでは,0.001より小さい確率を持つ例が外れ値とみなされる.低い確率の関数,外れ値決定境界線,データを可視化する.