使用 Transformer 神经网络
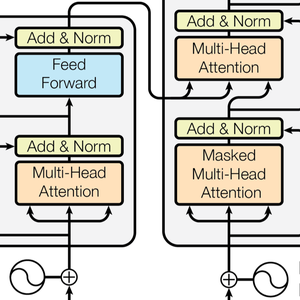
Transformer 神经网络是最近一类基于自我关注的、用于序列的神经网络,已被证明可以很好地适应文本,并且目前正在推动自然语言处理的重要进展。以下是开创性论文 Attention Is All You Need 中说明的的架构。
下面的例子演示了 transformer 神经网络(GPT 和 BERT),并展示了如何使用它们来创建自定义情绪分析模型。
从 Neural Net Repository 加载 GPT 和 BERT 模型。
在大量文本(通常有数十亿单词)上训练这些模型,完成无监督学习任务,如语言建模。因此,它们为各种任务提供了非常出色特征提取器。给定一个句子,这些模型输出一个数值向量列表,每个单词或子单词对应一个向量;这些向量是每个单词/子单词的“含义”的数值表示。
现在研究 BERT 网络的内部。可以通过单击感兴趣的部分网络(并再次单击进行更深层的探索)或用 NetExtract 完成此操作。
输入字符串首先被划分为单词或子单词。然后将每个 token(即单词或子单词)嵌入到大小为 768 的数值向量中。
然后,transformer 架构使用堆叠在一条链中的 12 个结构相同的自关注块来处理这些向量。这些块的关键部分是注意模块,由 12 个并行的自我注意转换 (self-attention transformation) 构成,也称为 "attention heads"。
提取其中一个 "attention heads"。 每个 head 以 AttentionLayer 为核心。简而言之,每个大小为 768 的向量通过确定哪些向量与自身相关来算出下一个值(也是大小为 768 的向量)。请注意这里使用了 NetMapOperator。
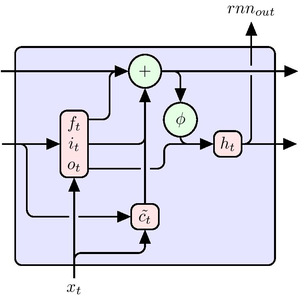
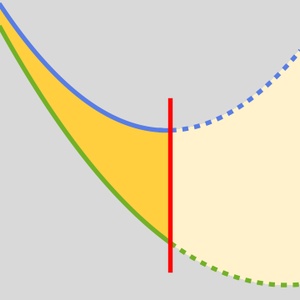
AttentionLayer 比循环层(如 LongShortTermMemoryLayer 和 GatedRecurrentLayer)以更直接的方式利用序列中的长期依赖关系。下图说明了各种序列架构的连接性。
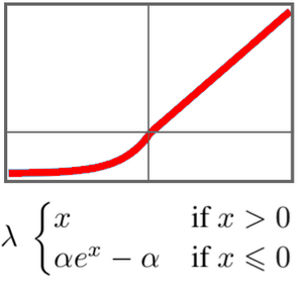
GTP 具有与 BERT 类似的架构。它的主要区别在于它使用因果自我关注 (causal self-attention),而不是简单的自我关注架构。从在 AttentionLayer 中使用 "Causal" 掩码这一点可以看出。
因果关注在进行文本处理时效率较低,因为给定的 token 无法获得有关未来 token 的信息。另一方面,文本生成需要因果关注:GPT 能够生成句子,而 BERT 只能对它们进行处理。
一些研究文章报道说,transformer 网络在许多语言任务中的表现优于循环网络。我们来看对经典电影情感分析的结果。
这里将 GPT 和 BERT 与基线 GloVe 单词嵌入和 ELMo 进行比较,ELMo 是 NLP 中具有当前技术水平的循环网络。
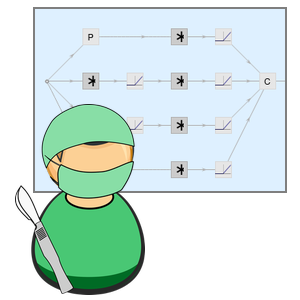
需要对一些网络做一下外科手术,以便它们能接受字符串作为输入,并输出向量序列。
我们可以尝试几种池化策略,从单词嵌入序列中创建一个句子分类器。
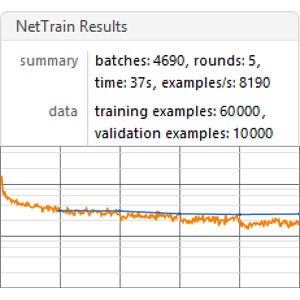
创建基准测试函数,根据给定的单词嵌入序列来训练和测量模型的性能。
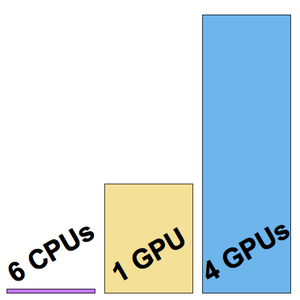
在所有单词嵌入序列上运行基准测试(建议使用 GPU)。
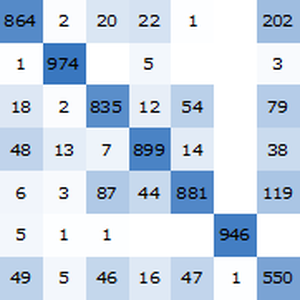
可视化基准测试报告。不出所料,基于最新的 transformer 网络的上下文单词嵌入优于基于循环网络的 ELMo 嵌入,显著优于传统的 GloVe(与上下文无关)嵌入。请注意,BERT 优于 GPT(15% 的错误率 vs 18% 的错误率),因为 GPT 受到因果约束的惩罚。