Transformer 신경망 사용하기
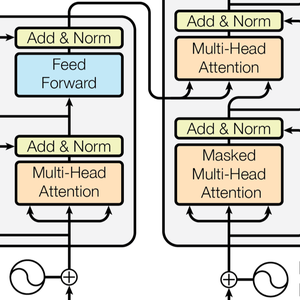
Transformer 신경망은 자기 주의에 기초한 순서를 위한 새로운 클래스의 신경망입니다. 이미 텍스트에 잘 적응하는 것으로 알려져 있으며, 현재 자연 언어 처리에서 중요한 진보를 가져왔습니다. 다음은 큰 영향을 미친 논문 Attention Is All You Need에 제시된 구조입니다.
이 예는 Transformer 신경망 (GPT와 BERT)을 입증하고 이들을 사용하여 사용자의 감정 상태 분석 모델을 어떻게 구축 하는지를 설명합니다.
GPT 모델과 BERT 모델을 Neural Net Repository에서 로드합니다.
이들 모델은 텍스트의 거대 코퍼스(보통 수십억 단어)에 의해 언어 모델링과 같은 비지도 학습으로 훈련되며, 결과적으로 다양한 작업에 사용 가능한 훌륭한 특징 추출기를 제공합니다. 이 모델은 문장이 주어지면 각 단어 또는 단어의 일부에 대해 하나의 수치 벡터를 목록으로 출력합니다. 이 벡터는 각 단어 혹은 단어의 일부인 "의미"의 수치 표현입니다.
이제 BERT 네트워크 속을 살펴봅니다. 이것은 네트워크의 흥미있는 부분을 클릭 (더 자세히 알고 싶으면 클릭을 반복)함으로써, 또는 NetExtract를 사용하여 실행할 수 있습니다.
입력 문자열은 먼저 단어 또는 단어의 일부로 토큰화되고, 그 다음 각 토큰은 크기 768의 수치 벡터에 삽입됩니다.
Transformer 구조는 다음으로 체인 형태로 쌓인 12개의 구조적으로 동일한 자기 주의 블록으로 벡터를 처리합니다. 이러한 블록의 중심 부분은 12개의 병렬 자기 주의 변환, 일명 "주의 헤드"로 이루어진 주의 모듈입니다.
이 주의 헤드 중 하나를 추출합니다. 각 헤드는 그 중심에서 AttentionLayer를 사용하고 있습니다. 간단히 말하면 768벡터의 각각이 어느 벡터가 그 자체와 관련되어 있는지를 판단함으로써 다음 값(여기서도 768벡터)을 계산합니다. 여기서 NetMapOperator가 사용되고 있음을 유의 해야합니다.
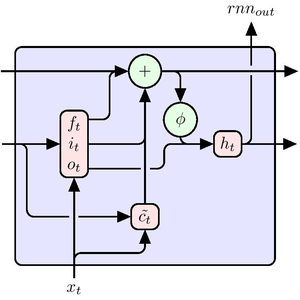
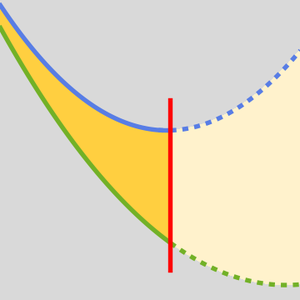
AttentionLayer는 시퀀스 중의 장기 의존을 LongShortTermMemoryLayer나 GatedRecurrentLayer의 순환층보다 훨씬 더 직접적인 방법으로 이용할 수 있습니다. 다음 그림은 다양한 시퀀스 구조의 접속성을 보여줍니다.
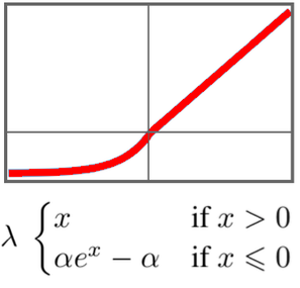
GTP는 BERT와 같은 구조입니다. 주된 차이는 GTP는 단순한 자기 주의 구조 대신에 인과적인 자기 주의 구조를 사용한다는 점입니다. 이는 AttentionLayer의 "Causal" 마스크를 사용하면 볼 수 있습니다.
인과 주의 구조는 주어진 토큰이 미래의 토큰 정보를 얻을 수 없으므로 텍스트 처리에서는 그다지 효율이 좋지 않지만, 텍스트 생성에는 필요합니다. GPT는 문장이 생성될 수 있지만 BERT는 문장을 처리할 수 있습니다.
몇몇 연구 논문은 많은 언어 작업에 대해 Transformer가 순환넷 보다 성능이 더 좋다고 보고하고 있습니다. 고전 영화의 감정 분석으로 이를 점검해 봅니다.
여기서는 GPT와 BERT가 기준이 되는 GloVe 단어 임베딩 및 ELMo와 비교되고 있지만 이는 자연어 처리에 있어서 순환넷에 대한 최첨단 기술입니다.
네트워크에 문자열을 입력으로 취하고 벡터 라인을 출력하도록 변경할 필요가 있는 경우도 있습니다.
일련의 단어의 매립에서 문장의 분류자를 만들기 위해 몇 가지 풀링법을 시도해봅니다.
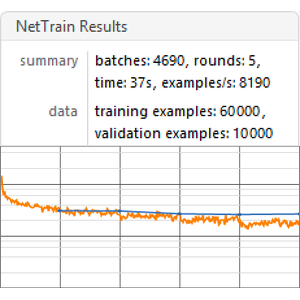
주어진 매립에 따라 모델의 성능을 훈련하고 측정하는 벤치 마크 함수를 만듭니다.
모든 내장 벤치 마크를 실행하는 GPU (권장)를 실행합니다.
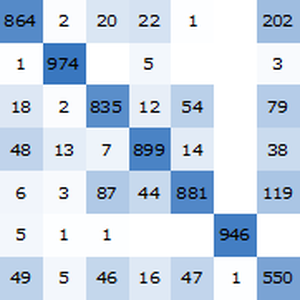
벤치 마크 보고서를 시각화합니다. 예상대로, 최신 Transformer를 기반으로하는 문맥상의 단어 매립은 순환 네트워크에 기초한 ELMo 매립보다 성능이 뛰어나고, 기존의 GloVe (문맥 독립적) 매립보다 성적이 좋습니다. GPT는 그 인과 관계의 제약에 의해 패널티가 부과되기 때문에, BERT는 GPT보다 성적이 좋은 (15% 대 18%) 점에 유의합니다.