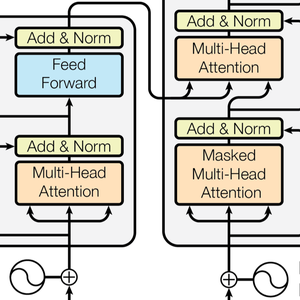
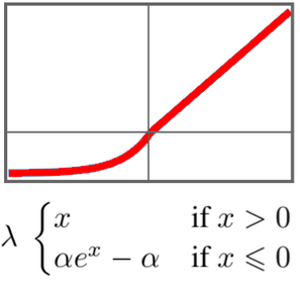
Neuronale Transformer-Netze verwenden
Neuronale Transformer-Netze sind eine neue Klasse von neuronalen Netzen für Sequenzen, die auf Selbst-Aufmerksamkeit basieren, sich gut mit Text anwenden lassen und derzeit wichtige Fortschritte in der natürlichen Sprachverarbeitung vorantreiben. Hier ist die Netzarchitektur, so wie sie im grundlegenden Paper Attention Is All You Need dargestellt wurde.
Dieses Beispiel zeigt neuronale Transformatorennetze (GPT und BERT) und veranschaulicht, wie sie zur Erstellung eines benutzerdefinierten Sentimentanalyse-Modells genutzt werden können.
Laden Sie die GPT- und BERT-Modelle aus dem Neural Net Repository.
Diese Modelle werden mit großen Textkorpora (normalerweise Milliarden von Wörtern) für unbeaufsichtigtes Lernen wie die Sprachmodellierung trainiert. Dadurch bieten sie hervorragende Feature-Extraktoren, die für verschiedene Aufgaben eingesetzt werden können. Bei einem Satz geben diese Modelle eine Liste von numerischen Vektoren aus, einen für jedes Wort oder jeden Wortteil. diese Vektoren sind eine numerische Darstellung der "Bedeutung" jedes Wortes/Wortteils.
Erkunden Sie nun das Innere des BERT-Netzwerks. Sie können dies tun, indem Sie auf den Teil des Netzwerks klicken, der Sie interessiert (und erneut klicken, um tiefer zu graben) oder indem Sie NetExtract verwenden.
Der Input-String wird zunächst in Wörter oder Teilwörter umgewandelt (tokenisiert). Jedes Token wird dann in numerische Vektoren der Größe 768 eingebettet.
Die Transformatorarchitektur verarbeitet dann die Vektoren mit 12 baugleichen Selbstaufmerksamkeitsblöcken, die in einer Kette gestapelt sind. Der Hauptbestandteil dieser Blöcke ist das Aufmerksamkeitsmodul, das aus 12 parallelen Selbstaufmerksamkeitstransformationen, auch bekannt als "Aufmerksamkeitsköpfe", besteht.
Extrahieren Sie einen dieser Aufmerksamkeitsköpfe. Jeder Kopf verwendet im Kern einen AttentionLayer. Kurz gesagt, jeder 768-Vektor berechnet seinen nächsten Wert (wieder ein 768-Vektor), indem er herausfindet, welche Vektoren für sich selbst relevant sind. Hierfür wird in diesem Beispiel der NetMapOperator verwendet.
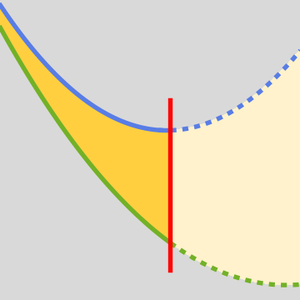
AttentionLayer kann langfristige Abhängigkeiten innerhalb von Sequenzen wesentlich direkter nutzen als rekurrente Schichten wie LongShortTermMemoryLayer und GatedRecurrentLayer. Die folgende Abbildung veranschaulicht die Konnektivität verschiedener Sequenzarchitekturen.
GPT hat eine ähnliche Architektur wie BERT. Der Hauptunterschied besteht darin, dass es eine kausale Selbstaufmerksamkeit anstelle einer einfachen Selbstaufmerksamkeitsarchitektur verwendet. Dies zeigt sich an der Verwendung der "Causal"-Maske in der Schicht AttentionLayer.
Die kausale Aufmerksamkeit ist bei der Textverarbeitung weniger effizient, da ein bestimmtes Token keine Informationen über zukünftige Token erhalten kann. Andererseits ist für die Textgenerierung kausale Aufmerksamkeit erforderlich: GPT ist in der Lage, Sätze zu generieren, während das BERT sie nur verarbeiten kann.
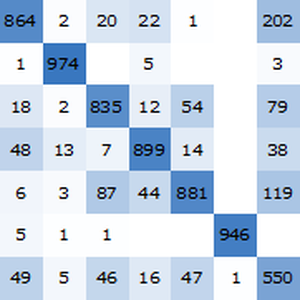
Mehrere Forschungsartikel berichten, dass Transformatoren bei vielen Sprachaufgaben die rekurrenten Netze übertreffen. Überprüfen Sie dies anhand einer klassischen Film-Sentimentanalyse.
Hier werden GPT und BERT mit den Worteinbettungs-Modellen GloVe und ELMo verglichen, die den aktuellen Stand der Technik für rekurrente Netze in NLP darstellen.
Manche Netze müssen noch etwas nachbearbeitet werden, so dass sie eine Zeichenkette als Eingabe nehmen und eine Folge von Vektoren ausgeben.
Versuchen wir mehrere Pooling-Strategien aus, um aus den Sequenzen von Worteinbettungen einen Satzklassifizierer zu machen.
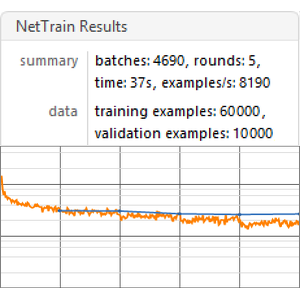
Erstellen einer Benchmarking-Funktion, die die Leistung eines Modells basierend auf einer bestimmten Einbettung trainiert und misst.
Führen Sie die Benchmark-Funktion (ein Grafikprozessor wird empfohlen) für alle Einbettungen durch.
Visualisieren Sie einen Benchmark-Bericht. Wie erwartet, übertreffen kontextabhängige Worteinbettungen auf Basis der neuesten Transformatoren die ELMo-Einbettungen auf Basis wiederkehrender Netze, die die klassischen GloVe (kontextunabhängige) Einbettungen deutlich übertreffen. Beachten Sie, dass BERT besser ist als GPT (15% gegenüber 18% Fehlerquote), da GPT eine Kausalitätsbeschränkung hat.