Use redes neurais com transformações
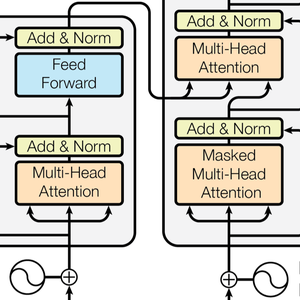
As redes neurais de transformadores são uma classe recente de redes neurais para sequências, baseadas na autoatenção, que funcionam bem com texto e que atualmente estão promovendo importantes progressos no processamento de linguagem natural. Aqui está a arquitetura representada no artigo seminal Attention Is All You Need.
Este exemplo demonstra as redes neurais do transformador (GPT e BERT) e mostra como elas podem ser usadas para criar um modelo de análise de opinião personalizado.
Carregue os modelos GPT e BERT do repositório de rede neural.
Esses modelos são treinados em grandes corpora de texto (normalmente bilhões de palavras) em tarefas de aprendizado não supervisionadas, como modelagem de linguagem. Como resultado, eles fornecem excelentes extratores de propriedades que podem ser usados para várias tarefas. Dada uma frase, esses modelos geram uma lista de vetores numéricos, um para cada palavra ou sub-palavra; esses vetores são uma representação numérica do "significado" de cada palavra/sub-palavra.
Agora explore o interior da rede BERT. Você pode fazer isso clicando na parte da rede em que está interessado (e clicando novamente para aprofundar) ou usando NetExtract.
A cadeia de caractere de entrada é convertida primeiro em palavras ou sub-palavras. Cada token é então incorporado em vetores numéricos de tamanho 768.
A arquitetura do transformador processa os vetores usando 12 blocos de auto-atenção estruturalmente idênticos agrupados em uma cadeia. O principal componente destes blocos é o módulo de atenção, constituído por 12 transformações de auto-atenção paralelas, também conhecidas como "cabeças de atenção".
Extraia uma dessas cabeças de atenção. Cada cabeça usa uma AttentionLayer em seu núcleo. Em suma, cada vetor 768 calcula seu próximo valor (um vetor 768 novamente) ao descobrir quais vetores são relevantes para si mesmo. Observe o uso do NetMapOperator aqui.
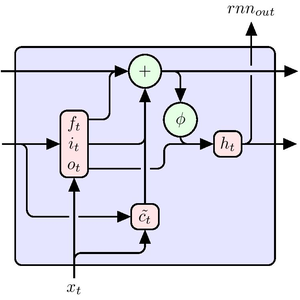
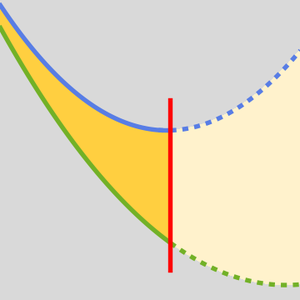
AttentionLayer pode explorar dependências de longo prazo nas sequências de uma maneira muito mais direta do que as camadas recorrentes, como LongShortTermMemoryLayer e GatedRecurrentLayer. A figura a seguir ilustra a conectividade de várias arquiteturas de sequência.
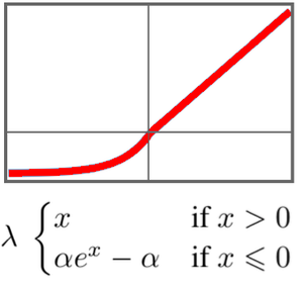
O GTP tem uma arquitetura semelhante ao BERT. Sua principal diferença é que ele usa uma auto-atenção causal, em vez de uma arquitetura simples de auto-atenção. Isso pode ser visto pelo uso da máscara "Causal" na AttentionLayer.
A atenção causal é menos eficiente no processamento de texto porque um determinado token não pode obter informações sobre tokens futuros. Por outro lado, a atenção causal é necessária para a geração de texto: o GPT é capaz de gerar sentenças, enquanto o BERT só pode processá-las.
Diversos artigos de pesquisa relatam que os transformadores superam as redes recorrentes para muitas tarefas de linguagem. Verifique isso em uma análise clássica de sentimentos de filmes.
Aqui, GPT e BERT são comparados com os modelos de incorporação de palavras GloVe e ELMo que representam as mais avançadas redes recorrentes em NPL.
Algumas das redes precisam de um pouco de operação para que considerem uma cadeia de caracteres como entrada e resultem uma sequência de vetores.
Vamos tentar várias estratégias de agrupamento para criar um classificador de sentenças a partir das sequências de incorporação de palavras.
Crie uma função de benchmarking que treine e faça a medida do desempenho de um modelo com base em uma determinada incorporação.
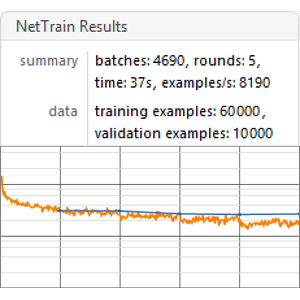
Execute a função de benchmark (um GPU é aconselhado) em todas as incorporações.
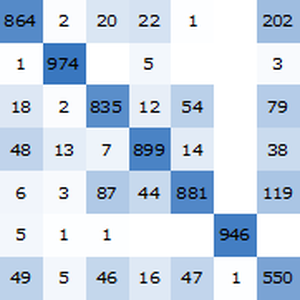
Visualize um relatório de referência. Como esperado, as incorporações de palavras contextuais baseadas nos transformadores mais recentes superam os envoltórios do ELMo baseados em redes recorrentes, que superam significativamente as incorporações clássicas de GloVe (independentes do contexto). Observe que o BERT é melhor que o GPT (15% versus 18% de taxa de erro), já que o GPT é penalizado por sua restrição de causalidade.