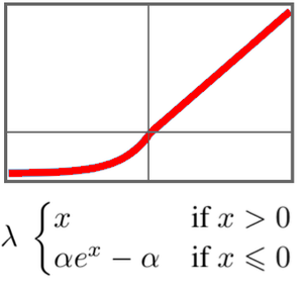
Transformerニューラルネットを使う
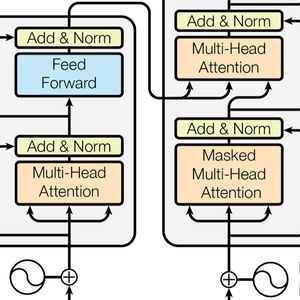
Transformerニューラルネットは,自己注意に基づくシーケンスのための新しいクラスのニューラルネットワークである.すでにテキストによく適応することが分かっており,現在自然言語処理において重要な進歩を推し進めている.次は,多大な影響を与えた論文「Attention Is All You Need」で示された構造である.
この例ではTransformerニューラルネット(GPTおよびBERT)を実証し,これらを使ってカスタムの感情状分析モデルをどのように構築するかを説明する.
GPTモデルとBERTモデルをNeural Net Repositoryからロードする.
これらのモデルは,テキストの巨大コーパス(通常数十億単語)によって,言語モデリングのような教師なし学習で訓練され,結果として,さまざまなタスクに使用可能な素晴らしい特徴抽出器を提供する.これらのモデルは,文が与えられると各単語または単語の一部について1つの数値ベクトルをリストとして出力する.これらのベクトルは各単語あるいは単語の一部の「意味」の数値表現である.
では,BERTネットワークの中を見てみよう.これは,ネットワークの興味ある部分をクリックする(より詳しく知りたければクリックを繰り返す)ことで,あるいはNetExtractを使って実行できる.
入力文字列は,最初に単語または単語の一部にトークン化される,次に,各トークンはサイズ768の数値ベクトルに埋め込まれる.
Transformer構造は,次に,チェーン状に積み重ねられた12の構造的に等しい自己注意ブロックでベクトルを処理する.これらのブロックの中心的部分は,12個の並列自己注意変換,別名「注意ヘッド」からなる注意モジュールである.
これらの注意ヘッドの一つを抽出する.各ヘッドはその中心部でAttentionLayerを使っている.簡単に言うと,768ベクトルのそれぞれが,どのベクトルがそれ自体に関連しているかを判断することによって,次の値(ここでも768ベクトル)を計算する.ここでNetMapOperatorが使われているのに注意のこと.
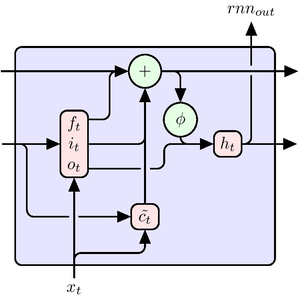
AttentionLayerはシーケンス中の長期依存を,LongShortTermMemoryLayerやGatedRecurrentLayerの回帰層よりはるかに直接的な方法で利用することができる.次の図は,さまざまなシーケンス構造の接続性を示している.
GTPはBERTと同じような構造である.主な違いは,GTPは,単純な自己注意構造の代りに因果的な自己注意構造を使う点である.これは,AttentionLayerの"Causal"マスクを使って見ることができる.
因果注意構造は,与えられたトークンが未来のトークンの情報を得られないので,テキスト処理ではあまり効率がよくないが,テキスト生成には必要である.GPTは文が生成できるがBERTは文が処理できるだけである.
いくつかの研究論文は,多くの言語タスクについてTransformerが回帰ネットよりも性能がよいと報告している.クラッシック映画の感情分析でこれをチェックする.
ここでは,GPTとBERTがベースラインのGloVe単語埋め込みとELMoと比べられているが,これは自然言語処理において,現在回帰ネットの最先端をいくものである.
ネットの中には,文字列を入力として取ってベクトル列を出力するように変更を加える必要があるものもある.
一連の単語の埋込みから文の分類子を作るために,いくつかのプーリング法を試してみよう.
与えられた埋込みに基づいてモデルの性能を訓練して測定する,ベンチマーク関数を作る.
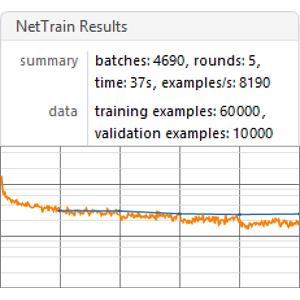
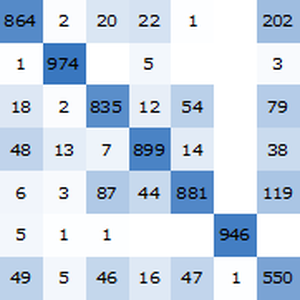
すべての埋込みにベンチマークを実行する(GPU推奨).
ベンチマークのレポートを可視化する.予想されるように,最新のTransformerに基づく文脈上の単語埋込みは回帰ネットに基づくELMo埋込みよりも成績がよく,後者は従来のGloVe(文脈非依存)埋込みよりも成績がよい.GPTはその因果関係の制約によってペナルティが科せられるので,BERTはGPTよりも成績がよい(15%対18%)ことに注意のこと.