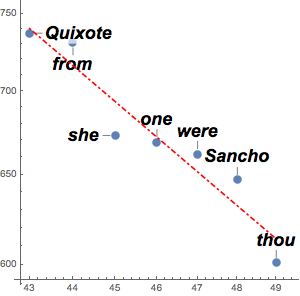
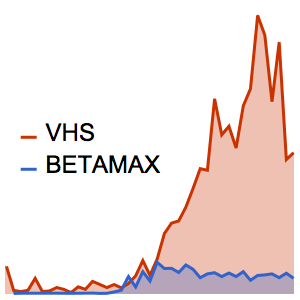
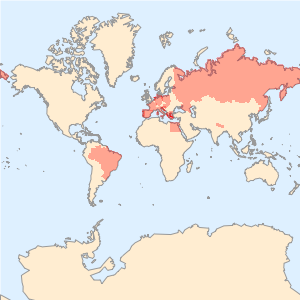
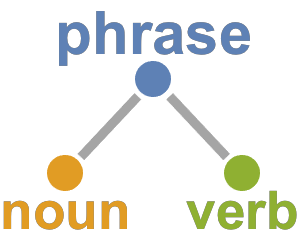
다국어 단어 목록의 계산
다양한 다국 언어의 단어 길이의 분포를 비교합니다.
In[1]:=
languages = {"German", "English", "Italian", "Dutch", "Russian"};해당 언어에 대해 사용 가능한 리스트를 얻고, 연상으로 컬랙트합니다.
In[2]:=
words = Association[# -> WordList[Language -> #] & /@ languages];각 단어의 길이를 비교합니다.
In[3]:=
wordLengths = StringLength /@ words;다음은 최소와 최대 단어의 길이를 표시한 것입니다.
In[4]:=
MinMax /@ wordLengthsOut[4]=
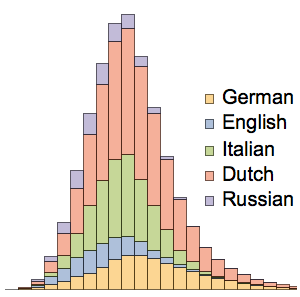
각 언어의 상대 빈도가 겹쳐진 히스토그램을 표시합니다. 러시아어와 영어는 짧은 단어의 비율이 높은 반면, 네덜란드어와 독일어는 긴 단어가 많음을 알 수 있습니다.
In[5]:=
Histogram[wordLengths, Automatic, "PDF", ChartLegends -> Automatic]Out[5]=
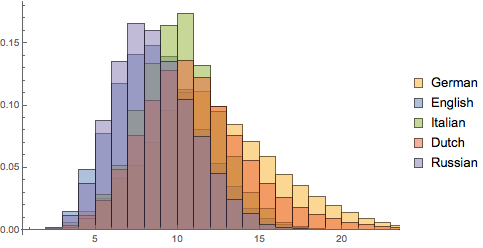
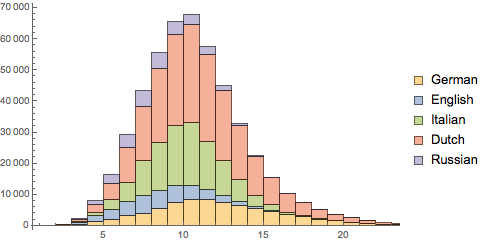
히스토그램을 함께 조합하여 모든 언어를 합한 길이의 수 전체를 표시합니다.
In[6]:=
Histogram[wordLengths, ChartLegends -> Automatic,
ChartLayout -> "Stacked"]Out[6]=