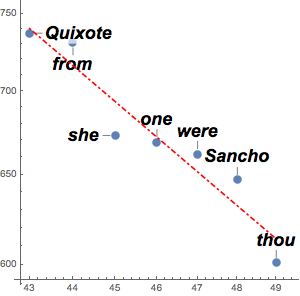
통시적 텍스트에서 단어의 빈도
버전 11은 WordFrequencyData를 사용하여 다양한 언어로 쓰여지고 출판된 텍스트에서 단어 빈도에 대한 정보를 수집합니다. 이 새로운 함수를 사용하여 단어의 통시적인 사용 경향을 추적합니다.
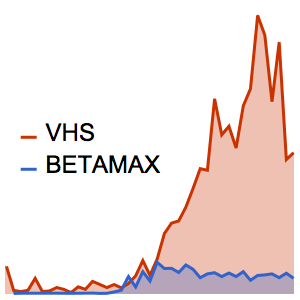
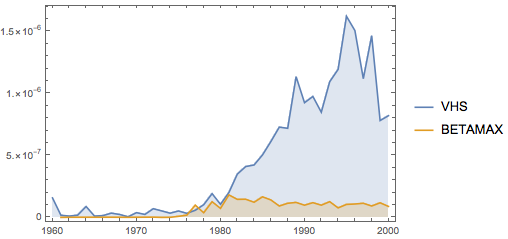
1960년부터 2000년까지 두가지 비디오 형식 이름의 사용량을 비교합니다.
In[1]:=

videoFormats = {"VHS", "BETAMAX"};
freqvideoFormats =
WordFrequencyData[videoFormats, "TimeSeries", {1960, 2000},
IgnoreCase -> True];In[2]:=
DateListPlot[freqvideoFormats, Filling -> Axis]Out[2]=
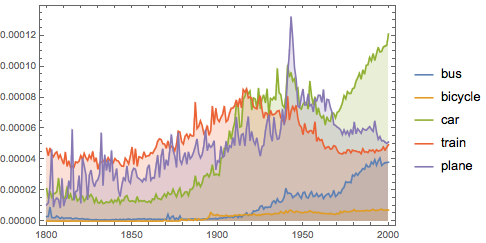
두세기에 걸친 다음의 교통 수단의 이름 사용 방법을 비교합니다.
In[3]:=

transports = {"bus", "bicycle", "car", "train", "plane"};
freqtransports =
WordFrequencyData[transports, "TimeSeries", {1800, 2000},
IgnoreCase -> True];In[4]:=
DateListPlot[freqtransports, Filling -> Axis]Out[4]=
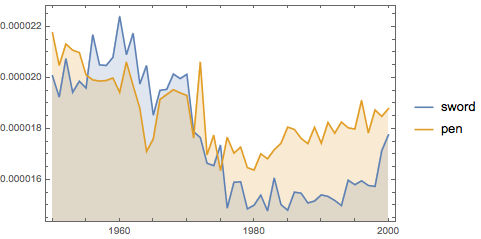
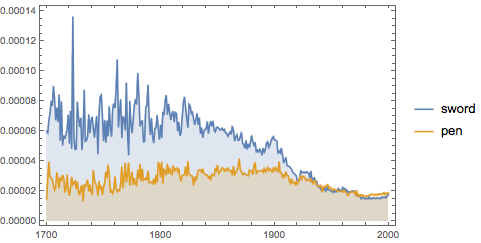
펜이 칼보다 최종적으로 언제 강해지는지를 구합니다.
In[5]:=
DateListPlot[
WordFrequencyData[{"sword", "pen"}, "TimeSeries", {1700, 2000},
IgnoreCase -> True], Filling -> Axis]Out[5]=
그리고 시간 윈도우를 축소하여 검이 언제 본래의 위치로 복귀하는지를 알아봅니다.
In[6]:=
DateListPlot[
WordFrequencyData[{"sword", "pen"}, "TimeSeries", {1950, 2000},
IgnoreCase -> True], Filling -> Axis]Out[6]=