문자열 분해
유전자의 염기 목록의 코돈 (연속 3개의 뉴클레오티드 그룹)의 상대 빈도를 조사합니다.
인간 유전자 "SCNN1A"의 DNA 서열을 얻습니다.
In[1]:=
dnasequence = GenomeData["SCNN1A", "FullSequence"];StringPartition을 사용하여 대응하는 코돈의 목록을 구축합니다.
In[2]:=
codons = StringPartition[dnasequence, 3];In[3]:=
Take[codons, 10]Out[3]=
이 유전자의 각 코돈의 상대 빈도를 계산합니다.
In[4]:=
frequencies = N[Counts[codons]/Length[codons]];A, C, G, T 뉴클레오티드에서 형성된 64개의 가능한 코돈이 있으며, 이들 모두는 선택한 유전자에 포함되어 있습니다.
In[5]:=
frequencies // LengthOut[5]=
빈도가 가장 높은 세개의 코돈을 구합니다.
In[6]:=
TakeLargest[frequencies, 3]Out[6]=
빈도가 가장 낮은 세개의 코돈을 구합니다.
In[7]:=
TakeSmallest[frequencies, 3]Out[7]=
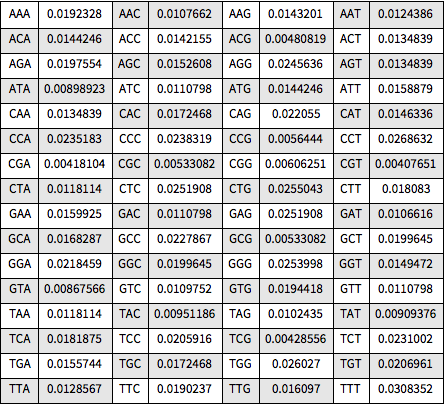
전체 상대 빈도를 Grid를 사용하여 시각화합니다.
전체 Wolfram 언어 입력 표시하기

Out[8]=