텍스트에서 국가 찾기
이 예에서는 TextCases의 다른 사용법, 이 경우 주어진 텍스트의 국가의 인식을 나타냅니다.
세개의 역사적 시대의 목록을 구축합니다.
In[1]:=

periods = {Entity["HistoricalPeriod", "EuropeanRenaissance"],
Entity["HistoricalPeriod", "AgeEnlightenment"],
Entity["HistoricalPeriod", "IndustrialRevolution"]};각각의 이름을 추출합니다.
In[2]:=
names = CommonName[periods]Out[2]=
WikipediaData를 사용하여 각각의 역사적 시대의 텍스트를 페이지에서 추출합니다.
In[3]:=
wikipages = WikipediaData /@ names;TextCases를 사용하여 각각의 페이지에 언급된 국가를 중복 항목은 삭제하고 추출합니다.
In[4]:=
countries =
DeleteDuplicates[TextCases[#, "Country" -> "Interpretation"]] & /@
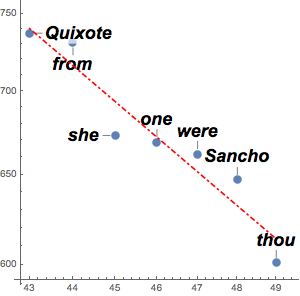
wikipages;예를 들어, 다음의 국가는 유럽 르네상스 시대의 페이지에 나타나는 국가의 목록입니다.
In[5]:=
First[countries]Out[5]=

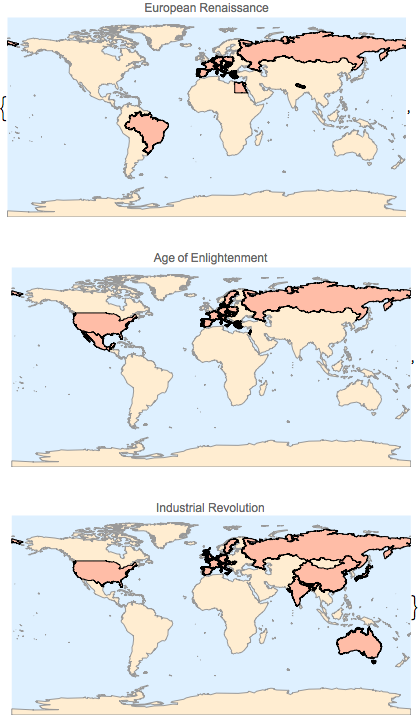
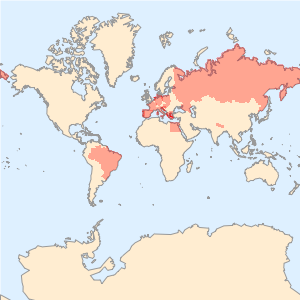
각각의 세계지도에 각각의 아티클에 언급된 국가를 플롯합니다.
전체 Wolfram 언어 입력 표시하기

Out[6]=