Gesprochene Ziffern klassifizieren
Das Framework für künstliche neuronale Netze (KNN) in der Wolfram Language ermöglicht leistungsstarke und benutzerfreundliche KNN-Trainingstools für Audio-Objekte. Dieses Beispiel trainiert ein Netz, um gesprochene Ziffern zu klassifizieren.
Rufen Sie die Spoken Digit Commands-Datensätze aus dem Wolfram Data Repository ab.
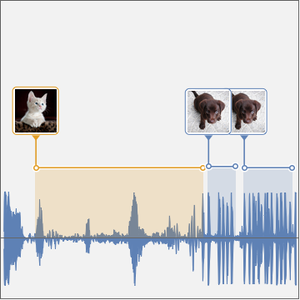
Der Datensatz besteht aus Aufzeichnungen der Ziffern 0 bis 9. Es handelt sich im Wesentlichen um ein Audioäquivalent zum MNIST-Digitaldatensatz.
Sie können damit beginnen, zu entscheiden, wie eine Aufzeichnung in etwas umgewandelt wird, das ein KNN verwenden kann. Der Netz-Encoder "AudioMFCC" wird verwendet, wobei das Signal in überlappende Trennwände aufgeteilt und eine Verarbeitung durchgeführt wird, um die Dimension zu reduzieren und gleichzeitig Informationen zu erhalten, die für das Verständnis des Signals wichtig sind.
Das Netzwerk wird auf einer einfachen NetChainaus GatedRecurrentLayers. basieren. Da Sie an einer einzelnen Klassifizierung interessiert sind, folgen den rekurrenten Schichten eine SequenceLastLayer-Schicht und ein linearer Klassifikator.
Sie können das Netz trainieren, so dass NetTrain sich um alle Hyperparameter kümmert.
Berechnen Sie mit NetMeasurements die Performance des Netzes.
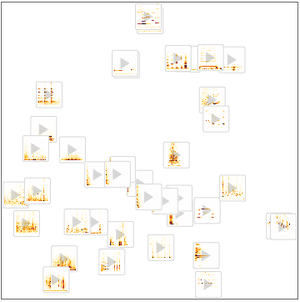
Durch das Entfernen der letzten Klassifizierungsebenen erhalten Sie einen Merkmals-Extraktor für Audiosignale.
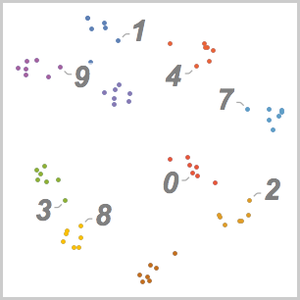
Verwenden Sie FeatureSpacePlot, um den Testdatensatz zu visualisieren, der in einen Merkmalsraum eingebettet ist, der durch das von Ihnen trainierte Netz definiert ist.