Stichwörter in gesprochener Sprache erkennen
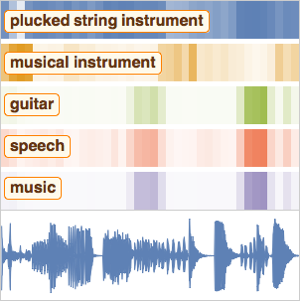
Neben einer einfachen Sprachtranskription sorgt die Berechnung der Wahrscheinlichkeit, dass eine Neukodierung des Sprechelements einen eingeschränkten Satz von Wörtern enthält, für weniger potentielle Rechtsschreibfehler. Darüber hinaus kann es sehr nützlich sein, herauszufinden, wo in einer Aufnahme ein bestimmtes Wort gesprochen wird.
Verwenden Sie das vortrainierte Spracherkennungsnetzwerk aus dem Wolfram Neural Net Repository, um die Wahrscheinlichkeit zu berechnen, dass eine Neukodierung ein bestimmtes Wort enthält. Die Details zu diesem Netzwerk finden Sie hier.
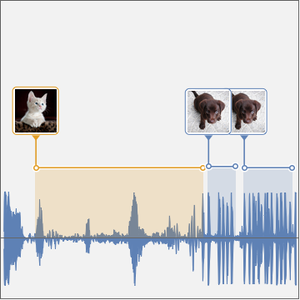
Laden Sie zunächst ein Beispiel aus den Trainingsdaten der "Spoken Digit Commands" aus dem Wolfram Data Repository herunter und schauen Sie es sich genauer an.
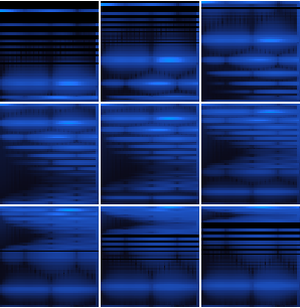
Berechnen Sie die Wahrscheinlichkeiten eines einzelnen Buchtsabens zu jeder Zeit mit Hilfe des Netzes.
Mit der Netzschicht CTCLossLayer können Sie die negative Log-Likelihood-Funktion einer bestimmten Buchstabenfolge bei der Ausgabe des Netzes berechnen.
Berechnen Sie die Log-Likelihood-Funktionen der Transkiption der Ziffern zwischen 0 und 9.
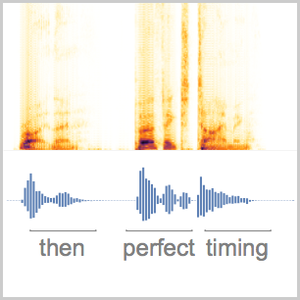
Sie können den gleichen Vorgang bei einem längeren Audiosample unter Zuhilfenahme eines Schiebefensters durchführen.
Berechnen Sie die Wahrscheinlichkeiten eines einzelnen Buchstabens zu jeder Zeit mit Hilfe des Netzes.
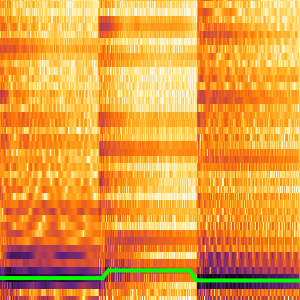
Wählen Sie die Transkriptionskandidaten aus.
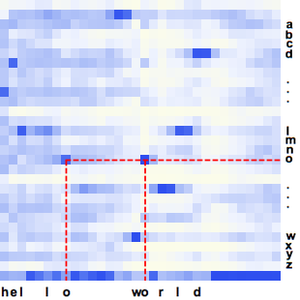
Sie können die vom Netz berechneten Wahrscheinlichkeiten partitionieren, um Teile des Signals zu untersuchen. Der CTC-Verlust kann in Bezug auf alle Optionen für jede Partition berechnet werden. Dies ergibt die Log-Likelihood, dass eine bestimmte Option die Transkription eines bestimmten Teils ist. BlockMap wird verwendet, um die Funktion auf die Teile des Audiosignals anzuwenden.
Sie können nun die Wahrscheinlichkeiten der drei Wörter als Funktion der Zeit darstellen.