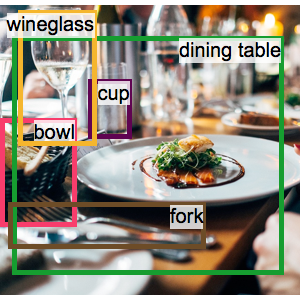
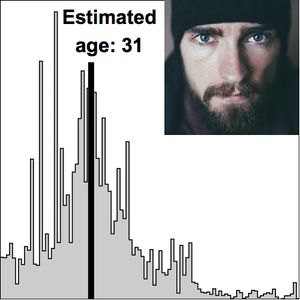
テキスト認識でラスタライズされたプロットを読む
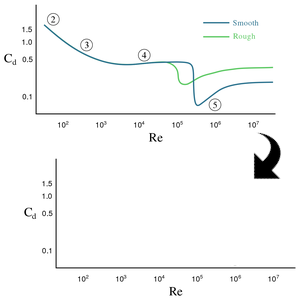
プロットを可視化するとラスタライズされた画像として保存されることがよくある.このようなプロットの主なソースはスキャナーあるいは古いドキュメントである.高解像度のプロットを構築するためには,ラスタライズされたプロットをベクタグラフィックスに変換する必要がある.この例では画像処理とテキスト認識を使って,横方向と縦方向の軸,軸のラベル,値の範囲を含むプロットの骨組みを抽出する方法を説明する.
プロットを含む画像を取る.
すべての目盛およびラベルの位置を認識し,それを連想に保存する.
付近の認識されたラベルを選び,x 座標と y 座標に従ってそれをグループ化する効用関数を定義する.
縦と横のラベルと目盛で認識されたものをグループ化する.
縦軸と横軸上の最大の座標を使った長方形を作ることで,画像の中のプロットの位置を求める.
画像の中のグラフィックスをハイライトする.
目盛を見付け解析する.
小さいユーティリティを使って,目盛として検出された文字列を数字に変換し,並べ替える.
軸のラベルを見付け,認識し,ハイライトする.
これでプロットの骨組みが再生成できるようになった.
もとの画像上では,横軸の200の目盛はゼロから少しシフトしている.どのくらいシフトしているかが分かったら,プロットの骨組み上でそれを再現することができる.
まず横軸の目盛と目盛の間がどのくらい離れているかを求める必要がある.
平均の距離を計算すると,どのように目盛が置かれるかの平均のスケールが分かる.
スケールを正しく計算するために,横の目盛を表す値と値の間の平均の差を求める必要がある.
最後に求めなくてはならないのは,軸の交点から最初の横軸の目盛までの距離(画素数)である.
これで必要なシフトが分かる.
これでもとの画像のように,横軸の200の目盛がゼロからシフトされた.
上で行ったすべてを1つの関数にまとめて,別のプロットの骨組みを認識してみる.