Ein selbstnormalisierendes Netz (SNN) trainieren
Die ersten vollständig verbundenen neuronalen Netze mit mehreren Schichten waren extrem schwierig zu trainieren. Alle tiefen Netze verwendeten eine Gewichtsverteilung (z.B. Faltung oder wiederkehrende Schichten). Außerdem hatten neuronale Netze Schwierigkeiten, mit traditionellen maschinellen Lernmethoden (Random Forest etc.) bei Aufgaben, die keine Wahrnehmungsaufgaben waren, zu konkurrieren. Die 2017 veröffentlichten selbstnormalisierenden neuronalen Netze (SNN) sind die erste neuronale Netzarchitektur, die es ermöglicht, tiefe, vollständig verbundene Netze zu trainieren, und auch die erste Architektur, die mit traditionellen Methoden für strukturierte Daten (typischerweise Reihen von Klassen und Zahlen) konkurriert. Dieses Beispiel zeigt, wie man ein solches Netz erstellt und trainiert.
SNNs sind eine sehr einfache Klasse von Netzwerken; sie verwenden nur lineare Schichten, eine elementare Nichtlinearität und eine modifizierte Version von "Dropout" zur Regularisierung. Konstruieren Sie einen SNN-Klassifikator aus sieben linearen Schichten.
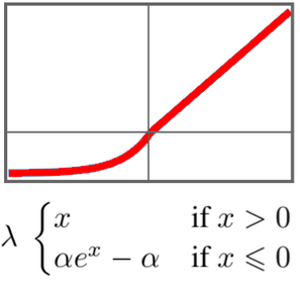
Das Schlüsselelement in diesem Netzwerk sind die "SELU" (Scaled Exponential Linear Unit)-Nichtlinearitäten. Die "SELU"-Nichtlinearität hat die Besonderheit, mit standardisierten Daten zu arbeiten und zu vermeiden, dass Gradienten zu klein oder zu groß werden.
Trainieren Sie dieses Netz mit der UCI Letter-Klassifikationsaufgabe.
Selbstnormalisierende Netze gehen davon aus, dass die Eingabedaten einen Mittelwert von 0 und eine Varianz von 1 haben, und standardisieren die Trainings- und Testdaten.
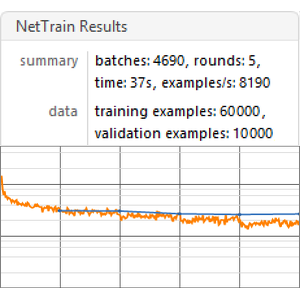
Trainieren Sie das Netz für 150 Runden, wobei 5 % der Daten für die Validierung übrig bleiben.
Verwenden Sie das Netz mit einem neuen Beispiel.
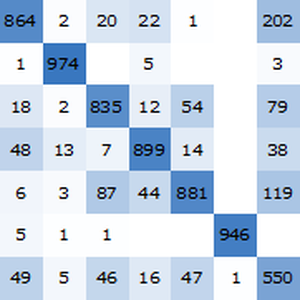
Ermitteln Sie die Genauigkeit des trainierten Netzes anhand der standardisierten Testdaten.
Die Genauigkeit des selbstnormalisierenden Netzes (ca. 96,4 %) ist im Vergleich zu klassischen maschinellen Lernmethoden gut.