Einen Agenten mit Methoden des bestärkenden Lernens trainieren
Dieses Beispiel zeigt, wie man ein einfaches neuronales Netz mit der REINFORCE-Methode (Williams, 1992) so trainiert, um erhaltene Belohnungen im "Simulated Cart Pole" zu maximieren. Die Umgebung des "Simulated Cart Pole" besteht aus einem Wagen, der sich entlang einer reibungslosen eindimensionalen Schiene bewegt, und einer gewichteten Stange, die über ein Scharnier (auch bekannt als umgekehrtes Pendel) am Wagen befestigt ist. Der Wagen hat eine bestimmte Anfangsgeschwindigkeit, so dass der Pol ohne Eingriff umkippt. Ziel des Mittels ist es, die Stange so lange wie möglich aufrecht zu halten. Dies wird erreicht, indem man lernt, welche von zwei möglichen Aktionen (nach links oder rechts bewegen) zu einem bestimmten Zeitpunkt durchgeführt werden soll.
Laden und renderen Sie die Umgebung in ihrem Anfangszustand.
Definieren Sie ein einfaches Netz, das eine Strategie lernt, um zu entscheiden, ob der Wagen nach links oder rechts bewegt werden soll.
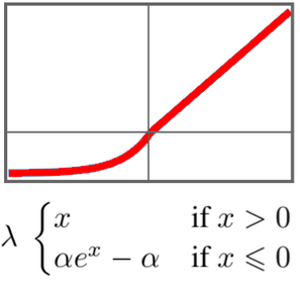
Definieren Sie eine Verlustfunktion für das Lernen von Strategiegradienten.
Definieren Sie eine Generatorfunktion, die Trainingsdaten für das Netz auswertet.
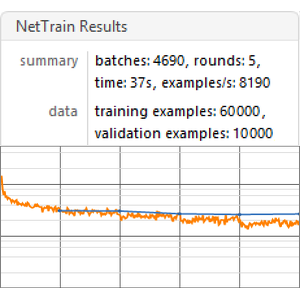
Trainieren Sie das Strategienetz und messen Sie den durchschnittlichen Diskontierungsfaktor.
Animieren Sie die Umgebung mit dem trainierten Policy-Netz (klicken Sie auf das folgende Bild, um eine Animation zu sehen). Beachten Sie, dass die Stange aufrecht steht.
Vergleichen Sie dies mit einem Agenten, der zufällige Aktionen in der Umgebung durchführt (klicken Sie auf das folgende Bild, um eine Animation zu sehen).