Einen Audio-Klassifikator trainieren
Dieses Beispiel zeigt, wie man ein einfaches neuronales Netzwerk für die Audio-Klassifizierung trainiert und wie man es für die Extraktion von Audio-Features verwendet.
Rufen Sie den Datensatz "Spoken Digit Commands" aus ResourceData auf, der aus Aufnahmen verschiedener Sprecher besteht, die Ziffern von 0 bis 9 aussprechen, zusammen mit ihren Labels (Klassenbezeichnungen) und einer Sprecher-ID.
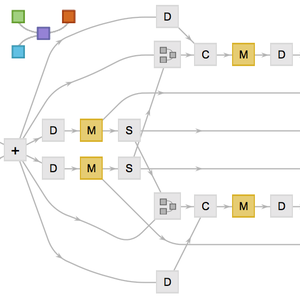
Die anfängliche Kodierung von Audiodaten ist komplexer und entscheidender als bei Bilddaten. Für Audio stehen verschiedene Kodierungsalgorithmen zur Verfügung, darunter "AudioMFCC", das eine kompakte Darstellung des Signals in Form einer Folge von Vektoren erzeugt.
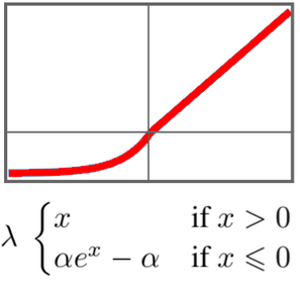
Definieren Sie ein Klassifizierungsnetzwerk basierend auf mehreren GatedRecurrentLayers. NetBidirectionalOperatorkann bidirektionelle Schichten verwenden, die Sequenz in beide Richtungen zu lesen und die Ergebnisse zu verketten. Der Endzustand des Wiederauftretens wird extrahiert durch SequenceLastLayer.
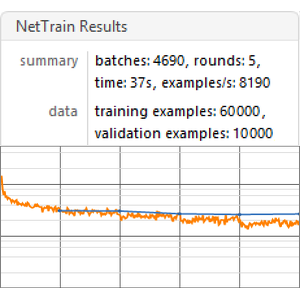
Trainieren Sie das Netz mit NetTrain und reservieren Sie 5 % der Daten für die Validierung.
Bewerten Sie das endgültige Netz anhand eines Beispiels aus dem Testdatensatz.
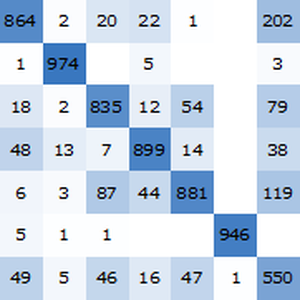
Berechnen Sie die Genauigkeit anhand des Testdatensatzes mit NetMeasurements.
Das Netz kann als High-Level-Feature-Extraktor verwendet werden, indem die letzten Klassifizierungsebenen entfernt werden.
Mit dem Extraktor kann ein neues Modell sehr schnell und mit geringem Datenaufkommen trainiert werden. Trainieren Sie beispielsweise mit Classify einen neuen Klassifikator mit Classify mit nur 50 Trainingsbeispielen.
Ermitteln Sie Performance-Informationen über den Klassifikator.