Distribution learning is another classic unsupervised learning task, which includes density estimation and generative modeling. As its name indicates, this task consists of learning the probability distribution of the data. Such a distribution can then be used, for example, to generate data, detect anomalies, or synthesize missing values. In a sense, distribution learning is a more rigorous version of dimensionality reduction since it also seeks to learn where the data lies but by using an actual probability distribution instead of a manifold.
Univariate Data
Let’s start with the simplest kind of data:
Here examples are categorical values (i.e. classes) that can either be "A" or "B". We assume that these examples are independently sampled from an unknown underlying probability distribution. Our goal is to estimate what this distribution is. Here the distribution is simple to express; we just need to determine the probabilities P("A") and P("B"). To do so, we can count the occurrences of each value:
To obtain probabilities, we need to normalize these counts so that they sum to 1:
And now we have a valid distribution, P("A")=0.375 and P("B")=0.625, which is known as a categorical distribution. We can use this distribution to sample synthetic examples:
We can also query the probability of a given example:
Let’s now do the same operation but for a univariate numeric dataset:
We can use a histogram to estimate the distribution that generated the data:
This time, the distribution is defined in a continuous domain, so we can compute a probability density:
Let’s visualize the probability density function (PDF) along with the training data:
From this distribution, we can compute the probability of an event, such as the probability that a random sample falls between -1 and 2:
This probability corresponds to the area under the PDF curve in the interval [-1,2].
A histogram is a kind of nonparametric distribution. We could also use a parametric distribution. Here is a function to automatically find a simple distribution that corresponds to the data:
In this case, the distribution found is a Gaussian:
Such a simple univariate distribution can already be useful for all sorts of things, such as representing the belief of a regression model. In machine learning, however, we are generally interested in higher-dimensional data, which means higher-dimensional distributions.
Fisher’s Irises
Let’s learn a distribution on Fisher’s Irises data:
The dataset is a record of 150 specimens of irises and their characteristics. To simplify the visualization, let’s only keep the sepal length and petal length:
The variables are numeric here, so we are going to estimate a continuous probability distribution. To do so, we use the automatic function LearnDistribution:
Let’s now see what we can do with this distribution.
Data Generation
One thing that every distribution can do is generate synthetic examples that are statistically similar to the original examples. Let’s generate (a.k.a. sample) 150 examples from this distribution:
Here is the original and synthetic data on the same graph:
As expected, these two sets are pretty similar. This ability to generate data is why such distributions are often called generative models. Generating synthetic examples can be an application in itself. For example, one might want to generate text or images automatically, which is possible nowadays using neural networks. Here is a painting generated by a generative neural network trained on portraits:

This painting has been sampled from a learned distribution (quite a bit more complex than ours!) and then printed. Often, such a generation is more useful when it is guided by humans, such as generating an image from its description. Such guided generations of complex data (e.g. image, text, and audio) are technically supervised learning tasks, but they use the same methods as pure (unsupervised) generative modeling.
Density Estimation & Likelihood
We can also use our learned distribution to query the probability density of a new example:
Because of this ability to compute a probability density, the task of learning a distribution is sometimes called density estimation. Let’s visualize the learned PDF along with the training data using a contour plot:
As expected, regions with a lot of training data have a high probability density and regions without training data have a low probability density. In a sense, this distribution tells us where the data lies, like a dimensionality reducer but in a more explicit way. This means that we can tackle the same kinds of tasks as with dimensionality reduction: anomaly detection, missing imputation, and noise reduction. However, we are not just using a manifold here but a full probability distribution, which means that for these tasks, the results obtained using a learned distribution are typically better than when using a dimensionality reducer.
From the density function, we can compute the likelihood, which is the most classic measure to assess the quality of a distribution. Let’s say that the following examples are a test set:
To compute the likelihood of the model on this test set, we first need to compute the PDF for every example:
Then we just need to multiply these densities:
Here we would like this value to be as high as possible. As in the case of classifiers or regression models, we usually report the (mean) negative log-likelihood (NLL):
Mathematically, this can be written as:
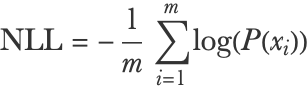
Here P(xi) is the PDF of test example xi and m is the number of test examples. A better model will typically have a lower negative log-likelihood, although “better” is application dependent, so we might sometimes want to use another measure. The negative log-likelihood is considered the most agnostic measure for distributions.
Anomaly Detection
Since the distribution tells us where the data lies, we can use it to detect anomalies. For example, let’s visualize the data example {6.5,2.5} along with the PDF of the distribution:
This example is clearly not in the same region as the training examples. It is an anomaly, also known as an outlier. Let’s compute the probability density of this anomaly:
We can compare this probability density with the density of the training examples:
As we can see, the PDF of the anomaly is much lower than for typical examples (although to be rigorous, we should compare it with test examples). This means that it is pretty easy to distinguish such an anomaly from regular examples by simply setting a threshold on the PDF. Such an anomalous example is said to be out-of-distribution or out-of-domain. There are various ways to define anomalies depending on the application, but in general, an anomalous example is rare and has different properties than regular examples, which is well captured by the “out-of-distribution” notion.
Since probability densities are hard to interpret (e.g. we can arbitrarily change them by rescaling the variables), we can instead compute the rarer probability of our anomaly, which is the probability that the distribution will generate a sample with a lower PDF:
This means that, according to our learned distribution, there is only a probability of about 10-12 (one chance in a trillion) for a random sample to be as extreme as our anomaly, which means that it is most certainly out-of-distribution and, therefore, an anomaly.
Note that we are detecting anomalies in an unsupervised way here, like we did with dimensionality reduction. This means that we make almost no assumptions on what anomalies are. This results in anomaly detectors that are pretty robust at detecting new kinds of anomalies, but this might not be the best method if anomalies tend to be similar to each other. In that case, it would probably be better to learn an anomaly detector in a supervised way, which means training a regular classifier.
A downside of learning an anomaly detector in an unsupervised way is that it can require a bit more work from us. For example, if we know that a feature is not relevant for the type of anomalies we are looking for, it is important to remove this feature from the data. Supervised learning does not have this problem since it automatically learns which features are important and which ones are not. This echoes similar issues present in clustering and dimensionality reduction. Generally speaking, unsupervised learning is more of an art than supervised learning.
Missing Data Synthesis
Another important application of distribution learning is the imputation of missing data. Let’s say that one of our examples has a sepal length of 5.5 centimeters and that its petal length is unknown:
It is important to know why a value is missing. Maybe the measurement tool could not measure the length of the petal because the petal was too small, or maybe the shape of the petal was strange, or maybe it was half eaten by a bug. In such cases, machine learning is not going to be very helpful, and one should rely on ad hoc ways of handling the missing value. Here we are going to assume that the reason for the missing value has nothing to do with the example itself. For example, it could occur if the value was mistakenly deleted after the recording. In statistical terms, this is called missing completely at random. Let’s compute a plausible value for the petal length under this assumption.
We know that the sepal length is 5.5 centimeters, so the unknown example must be on this line:
According to our assumption, the unknown example has been generated from the same underlying distribution as the training examples, which means that the probability density of the unknown petal length is proportional to the density along the “sepal length = 5.5 cm” line. Let’s plot this density using our learned distribution:
This corresponds to our belief about the missing value, which is our learned distribution conditioned on a sepal length of 5.5 centimeters (up to a multiplicative factor since it is not normalized here).
Now that we know the probability distribution for the missing value, we can synthesize a value. We could, for example, use the value that has the highest density, which is called the mode of the distribution. In this case, the mode is around 1.43 centimeters:
However, using the mode is often not ideal. For example, we can see here that the distribution is bimodal, which means it has two peaks, and the probability mass of the second peak (its area) is actually higher than the probability mass of the first peak. This means that it is likely that the real value is in the second peak and, therefore, far from the mode. To circumvent this, we could use the mean, but such a mean (around 3.05 centimeters) also happens to be in an unlikely region.
Often, the best way to synthesize missing values is to use a random sample from the conditioned distribution. The function SynthesizeMissingValues does this random sampling by default:
Let’s check that the random samples are from the correct distribution by repeating the process several times and plotting a histogram of the results:
Using a random sample might appear foolish, but it is often good enough and has the advantage of not introducing much bias to the data. Also, this method allows for obtaining several possible missing values, which can then be used to obtain uncertainties on whatever downstream computation we need to do. For example, let’s imagine that we need to multiply the sepal length and petal length. We can synthesize the missing value several times in order to obtain a statistical uncertainty on the result:
We can even plot a histogram of the results under all these different imputations:
This method allows for the propagation of our uncertainty about the missing value in the final result.
Missing Data Synthesis
We have seen how to impute data using a learned distribution, but what if the training data has missing values itself? For example, let’s consider the Titanic dataset:
Here is a random sample of five passengers:
We can see that some ages are missing. If we had a learned distribution, we could impute these values, but most distribution learning methods require all of the values to be present. To solve this problem, we can use the classic expectation-maximization (EM) algorithm. There are several ways to understand the EM algorithm. The simplest and most practical one is to see it as a self-training procedure that alternates missing imputation and distribution learning. For example, we could start the process by imputing missing values in a naive way:
Here are our five examples now:
Then, we can use this data to learn a distribution:
We can then use this distribution to re-impute the missing data in the original dataset:
Here are our five examples again:
And we could repeat this procedure several times until the imputed values do not change.
Such a procedure is called a hard EM algorithm because we replaced each missing value with a unique sample. The full EM algorithm would consist of obtaining several samples for each missing value and learning the distribution using all of these possible imputations. For some distribution learning methods, it is even possible to compute the exact updated distribution without having to rely on samples. The name of the EM algorithm comes from its two distinctive steps; the imputation step is called the expectation step and the learning step is called the maximization step.
The EM algorithm is a classic algorithm in machine learning. Besides imputing missing data in generic datasets, it is used in the classic clustering methods of k-means and the Gaussian mixture model. The idea here is to see the clustering task as a distribution learning task for which cluster labels are missing. Another use of the EM algorithm is in semi-supervised learning to impute missing labels.
Note that the EM algorithm is a local optimization algorithm, so it might get stuck in a local optima. Overall, this algorithm works well if the number of missing values is not too large and if the initialization (the naive imputation) is sensible.
LearnDistribution actually uses the EM algorithm under the hood, so we don’t have to do this procedure here and can directly impute missing data:
Here the imputation is made using random samples from the conditioned distribution. We could also decide to impute with the most likely values (which introduces statistical biases though):
Using learned distributions to impute missing values is generally the best approach.
Anomaly Detection
Let’s now see a more realistic example of how to detect anomalies with a distribution. We will use the CIFAR dataset, which is a collection of 50000 small images:
Here are 20 examples from this dataset:
Let’s train a distribution on these images:
As a sanity check, let’s look at the learning curve:
Here the reported cost is related to the negative log-likelihood, which we should compare to a baseline to know if it is good or not. We can see that the loss is decreasing with the number of training examples, so the model seems to take advantage of the data, and we would probably gain by training with more data. Let’s generate samples from this distribution:
As we can see, the samples have some structure: nearby pixels are correlated and we can see patches of different colors. However, these samples are far from realistic images. To obtain realistic images, we should use more advanced methods, such as generative neural networks; should probably use more data as well; and should definitely use more computing power. Nevertheless, this does not mean that this distribution is useless. Let’s see if it can detect anomalies.
To detect anomalies, we transform the learned distribution into an anomaly detector:
This detector computes the rarer probability of each example and classifies it as anomalous if the rarer probability is under 0.001. Let’s use it on some test examples:
As expected, all of the examples are non-anomalous. Let’s now corrupt these examples and apply the anomaly detector again:
Now seven examples out of 10 are anomalous. If we change the rarer probability threshold to a higher value, such as 0.01, all of them would be considered anomalies:
The downside of raising this threshold is that many non-anomalous examples will now be classified as anomalous. Let’s check how many examples are like this in the full test set (10000 examples):
About 0.5% of the examples are wrongly classified as anomalies, which is close to the 1% that we were expecting from setting the rarer probability threshold to 0.01. This rarer probability threshold is a way for us to trade false negatives for false positives. The choice of threshold depends on how easy it is to find the anomalies. For example, let’s plot the rarer probability as function of the level of jittering that we apply:
If the anomalies typically have a rarer probability of 10-8, we can allow ourselves to use a low threshold and the current model would work just fine. If the rarer probabilities of anomalies are around 0.01 or 0.001, however, we would either need to find a false positives/false negatives compromise or we would need to learn a better distribution.
| ■ | Distribution learning is the task of estimating the underlying probability distribution that generated a dataset. |
| ■ | Like dimensionality reduction, distribution learning can be seen as a way to learn where the data lies. |
| ■ | A learned distribution can be used to generate new examples statistically similar to training examples. |
| ■ | A learned distribution can be used to synthesize missing values. |
| ■ | A learned distribution can be used to detect anomalies. |
| probability distribution | mathematical object that gives the probabilities of occurrence of possible outcomes of a random phenomenon, can also be used to generate random outcomes from this phenomenon | |
| probability density function | probability distribution for numeric continuous variables | |
| to sample from a distribution | to generate a random outcome (a.k.a. sample) from the probability distribution | |
| generative models | models that can generate samples from a distribution | |
| distribution learning density estimation generative modeling | task of estimating the probability distribution from which some data has been generated | |
| categorical distribution | probability distribution of a categorical random variable | |
| anomaly outlier | data example that substantially differs from other data examples | |
| anomaly detection | task of identifying examples that are anomalous | |
| rarer probability | probability that the distribution will generate a sample with a lower PDF than the PDF of a given example | |
| imputation missing data synthesis | task of synthesizing the missing values of a dataset | |
| missing completely at random | when the reason for a missing value has nothing to do with the unknown value or with any other value of the data example | |
| conditioning a distribution | setting a variable of a distribution to a given value, hence defining a new distribution on the other variables | |
| distribution mode | outcome of a distribution that has the highest probability or probability density | |
| expectation-maximization (EM) algorithm | classic method to learn a distribution when values are missing, alternates missing imputation and distribution learning |