Subsecuencia común de genes de ADN
Las funciones de la versión 7 LongestCommonSequence y LongestCommonSubsequence ahora están complementados por sus contrapartes posicionales LongestCommonSequencePositions y LongestCommonSubsequencePositions.
Compare las subsecuencias de ADN de genes aleatorios del cromosoma Y.
In[1]:=
genes = RandomSample[GenomeData["ChromosomeYGenes"], 4]Out[1]=
Agrupe estos genes en pares.
In[2]:=
With[{subsets = Subsets[genes, {2}]},
Table[pair[i] = subsets[[i]], {i, 1, Length[subsets]}]];Defina una función que obtendrá las posiciones de secuencia de ADN continua más larga común para cada par, junto con la secuencia misma.
In[3]:=

commonDNASubequence[{g1_, g2_}] :=
With[{d1 = GenomeData[g1], d2 = GenomeData[g2]}, {{g1, g2},
LongestCommonSubsequencePositions[d1, d2],
LongestCommonSubsequence[d1, d2]}]La subsecuencia común más larga del primer par.
In[4]:=
commonDNASubequence[pair[1]]Out[4]=
La subsecuencia común más larga del segundo par.
In[5]:=
commonDNASubequence[pair[2]]Out[5]=
La subsecuencia común más larga del tercer par.
In[6]:=
commonDNASubequence[pair[3]]Out[6]=
La subsecuencia común más larga del cuarto par.
In[7]:=
commonDNASubequence[pair[4]]Out[7]=
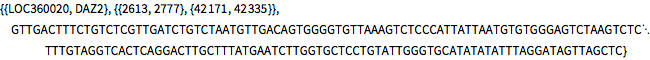
La subsecuencia común más larga del quinto par.
In[8]:=
commonDNASubequence[pair[5]]Out[8]=
La subsecuencia común más larga del sexto par.
In[9]:=
commonDNASubequence[pair[6]]Out[9]=
In[10]:=
commonDNASubequence[pair[6]]Out[10]=