Das Zipfsche Gesetz
Das Zipfsche Gesetz besagt, dass die Häufigkeit eines Wortes im Korpus einer Sprache umgekehrt proportional zu dessen Rangfolge ist. Dieses Beispiel illustriert mithilfe der neuen Funktionen WordCount und WordCounts das Gesetz mit Wörtern, die in Miguel de Cervantes' Roman Don Quixote vorkommen.
ExampleData enthält den spanischen Text des ersten Bands von Don Quixote.
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];Das Beispiel umfasst mehr als 180.000 Wörter.
WordCount[textSpanish]Das Vorkommen jedes einzelnen Wortes wird durch WordCounts als Assoziation gegeben. Das Ergebnis ist bereits in absteigender Reihenfolge sortiert.
association = WordCounts[textSpanish];Take[association, 10]Ermitteln Sie die Häufigkeit der 1000 häufigsten Wörter.
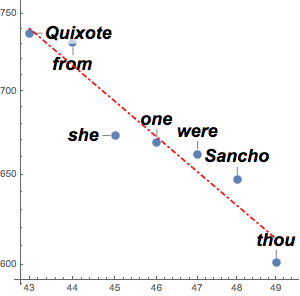
counts = Take[Values@association, 1000];Um diese Häufigkeiten mit einem Potenzgesetz anzunähern, ermitteln Sie Logarithmen zur linearen Modellanpassung. Das Zipfsche Gesetz besagt, dass der Exponent bei -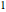 liegen soll, und das Ergebnis liegt nahe an diesem Wert.
liegen soll, und das Ergebnis liegt nahe an diesem Wert.
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Visualisieren Sie das Modell gemeinsam mit den Daten.

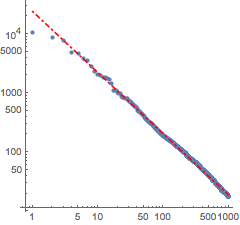
Das Zipfsche Gesetz bewahrheitet sich in jeder Sprache. Daher wird dieselbe Berechnung nun auch mit der englischen Version von Don Quixote durchgeführt.
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];Take[associationEnglish, 10]Auch hier liegt der gefundene Exponent nahe bei 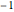 .
.
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]