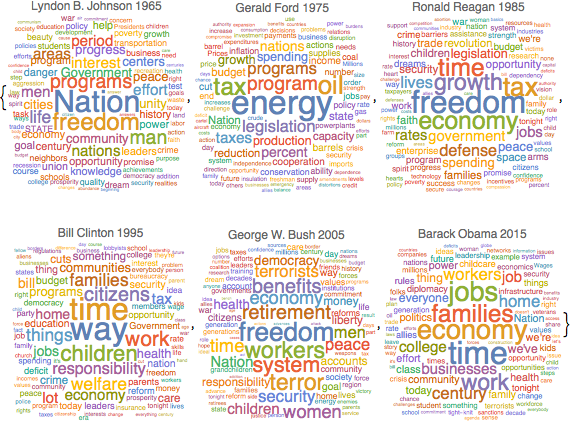
Häufigkeit von Nomen in Reden
Extrahieren Sie mit TextCases Teilstrings einer bestimmten Wortart, z.B. Nomen oder Verben, aber auch Länder, E-Mailadressen etc.
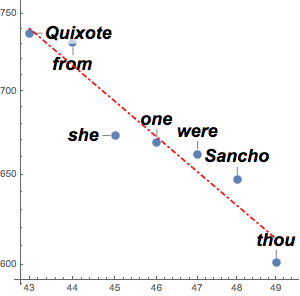
Erstellen Sie einen Datensatz aller Reden, die je von US-Präsidenten vor dem US-Kongress gehalten wurden.
In[1]:=
data = ResourceData["State of the Union Addresses"];Reduzieren Sie die Größe des Datensatzes, indem Sie nur die Namen der Präsidenten, Jahreszahlen der Reden und Text der Reden berücksichtigen.
In[2]:=
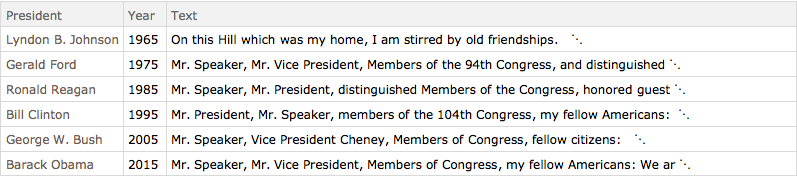
reduceddata = data[All, {"President", "Year", "Text"}];Beschränken Sie sich auf Reden in 10-Jahres-Intervallen.
In[3]:=
years = Range[1965, 2015, 10];
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=
Identifizieren Sie mit TextCases die Nomen in jeder Rede.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];Zählen Sie, wie oft die unterschiedlichen Nomen pro Rede vorkommen.
In[5]:=
freqnouns = Counts /@ nouns;Ignorieren Sie Wörter, die in den meisten Reden sehr oft vorkommen.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];Generieren Sie Schlagwortwolken zur Veranschaulichung der Häufigkeit bestimmter Nomen im Lauf der Zeit.
Den kompletten Wolfram Language-Input zeigen

Out[7]=